2026-05-21 · Industry
Lokaliseringskvalitetssäkring för SaaS-team: vad du kontrollerar innan du lanserar
73 % av SaaS-teamen hittar fel via användarrapporter, inte via QA. Lär dig hur lokaliseringens kvalitetssäkring fångar trasiga variabler, HTML, ordlista och längd.

En infödd granskare redigerar en AI-översatt sträng och döper om
{userName}till{användarNamn}. Variabeln löses inte längre upp. Etiketten visar nu{användarNamn}i produktion för varje fransk användare. Manuell granskning godkände det: granskaren läste för att förstå innebörden. En automatiserad kontroll hade fångat det på under en sekund.
Vad lokaliseringskvalitetssäkring faktiskt innebär
Lokaliseringskvalitetssäkring är processen att verifiera att översättningar är korrekta innan de når användarna. Det täcker både översättningskvalitetssäkring (är innebörden korrekt?) och strukturell integritet (är variabler, taggar och ordlisteord intakta?). Det är två separata jobb med två olika verktyg: automatiserade kontroller för strukturfel och mänsklig granskning för språkliga bedömningar.
De flesta team blandar ihop dem. De skickar strängar till en tvåspråkig teammedlem och kallar det klart. Granskaren fångar tonproblem. De fångar inte en saknad variabel, för de läser för innebörden, inte för att köra en mönstermatchning.
Siffrorna bekräftar detta. En 2026 års undersökning bland 1 000 ingenjörs- och produktteam visade att 73 % hittar översättningsfel i produktion via användarrapporter (IntlPull, State of i18n 2026). Inte via QA. Inte via testning. Via användarklagomål. Samma undersökning visade att 52 % inte har någon systematisk QA-process utöver manuella stickprov.
Manuella stickprov är ingen QA-process. Det är ett lotteri.
Strukturfelen är de som är värda att automatisera. Så här ser de ut.
De fem typerna av lokaliseringskontroller
Varje översättningssträng passerar fem automatiserade kontroller innan en mänsklig granskare ser den. Var och en fångar en felklass som manuell granskning konsekvent missar.
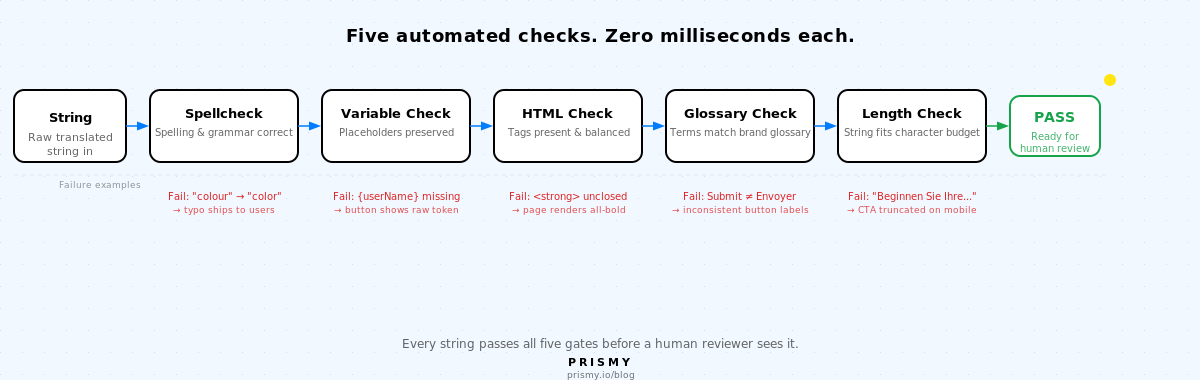
1. Stavningskontroll
Varje översättningsnyckel måste vara fri från stav- och grammatikfel.
Felmönstret: en AI-översatt sträng eller en mänsklig redigering introducerar ett stavfel, en felaktig verbform eller ett grammatikfel som går obemärkt förbi eftersom ingen aktivt letar efter det. Manuell granskning fångar många av dessa, men granskare som läser för innebörden missar subtila fel, särskilt i språk de inte är helt flytande i.
Automatiserad stavningskontroll körs på varje översättningsnyckel i varje locale innan strängen når en granskare. Den flaggar stavfel och grundläggande grammatikproblem på under en millisekund, i skala, i varje språk parallellt.
2. Variabelbevarende
Varje interpolationsplatshållare i källsträngen måste finnas i den översatta strängen med rätt format.
Felmönstret: en infödd granskare redigerar en AI-översatt sträng och döper om variabeln: {userName} blir {användarNamn}, eller de tar bort den helt vid omformulering. Variabeln löses inte längre upp. I produktion ser användarna den råa platshållaren istället för sitt namn. AI-översättning hanterar detta korrekt; felet introduceras när en människa redigerar resultatet utan att inse att variabeln är nödvändig.
Det här är automatiserbart med en enkel mönstermatchning. Kontrollen körs på under en millisekund. Samma undersökning visade att 61 % av teamen har upplevt trasiga platshållarvariabler i produktion. Var och en av dessa fel passerade en mänsklig granskning.
3. HTML- och taggintegritet
Varje HTML-tagg i källsträngen måste finnas och vara balanserad i översättningen.
Felmönstret: en översättare arbetar i klartext-läge, eller ett maskinöversättningssystem tar bort en avslutande tagg när strängen rekonstrueras. Källan lyder Your subscription is <strong>active</strong>. Översättningen lyder Din prenumeration är <strong>aktiv. </strong> saknas. Resten av sidan renderas i fetstil.
Automatiserade taggbalansekontroller fångar detta. 41 % av teamen har skickat trasiga översättningar som brutit UI-layouten, enligt samma undersökning. HTML-taggförlust är en av de vanligaste orsakerna.
4. Ordlistekonsistens
Varje term i varumärkesordlistan måste visas med sin korrekta översättning på varje språk, konsekvent i alla strängar.
Utan en ordlistekontroll tar översättare oberoende beslut på ordnivå. «Submit» blir «Skicka» i en sträng och «Publicera» i en annan. «Free trial» blir «gratis provperiod» på prissättningssidan och «gratis testning» i onboarding-flödet. Användare märker det. Supportärenden nämner «den förvirrande knappen».
58 % av teamen rapporterar felaktig terminologi och inkonsekventa termer som en produktionsfeltyp. Lösningen är inte bättre översättare. Det är en ordlista som utvärderaren kontrollerar på varje sträng.
Det riktiga arbetet görs på ordlistan. Vi måste säkerställa att översättningar av nyckeltermer är korrekta i det nya språket. Det är där vi spenderar mest tid.Alexis Toyane, Product Lead på Figures
Figures skalade från två språk till nio. Ordlistan var inte omkostnaden. Det var grunden. Se hur de kom dit: Figures skalade till nio språk.
5. Längd och overflow
Den översatta strängen måste passa UI-elementet den ska fylla. Tyska texter är 30-40 % längre än engelska. Japanska kan vara kortare men kräver andra radhöjdsregler.
Ingen kontrollerar längden förrän strängen är i den körande appen. TMS:en visar den råa strängen, inte den renderade knappen. En tysk call-to-action som borde lyda «Start your free trial» blir «Beginnen Sie Ihre kostenlose...» och kapas vid knappens kant. Den primära CTA:n är osynlig på en av dina toppmarknader.
67 % av teamen har upplevt textoverflow och trunkering i produktion. Att sätta teckensaldon per sträng och kontrollera dem på strängnivå fångar lång-svansen innan renderingen.
Varför manuell granskning missar strukturfel
En mänsklig granskare läser för innebörden. De fångar en tonmismatch, ett kulturellt felsteg, en mening som låter styv på portugisiska. De fångar inte {userName} som sitter olöst i strängen, för de läser det omedvetet som ett ifyllt värde.
Granskare arbetar också i skala: 20-50 strängar per timme är ett realistiskt tempo för noggrann granskning. En release med 50 strängar på fem språk innebär 250 stränggranskningar. Strukturkontroller körs på samma 250 strängar på millisekunder.
Data från Common Sense Advisorys 2025 undersökning är tydliga: automatiserad QA fångar 70-80 % av alla översättningsproblem, ökande till 90-94 % för team med strikt ordlistehantering. Återstående 6-30 % är språkliga och kulturella, och kräver mänsklig bedömning. Det är arbetsfördelningen.
Kostnadskalkylen stänger frågan. Att åtgärda ett översättningsfel efter att det nått produktion kostar 8-12 gånger mer än att fånga det under översättning (Nimdzi). För ett team med fem språk och två releaser per månad förändras den kalkylen snabbt.
Du har tre vanliga utgångspunkter:
Om du har en manuell process: din tvåspråkiga granskare fångar de språkliga 20 %. De strukturella 80 % skickas. Variabeln din granskare inte märkte visas nu för 2 000 tyska användare.
Om du har ett enterprise-TMS: din QA-flik finns, men körs inuti en plattform. Om strängar kopieras ut ur TMS:en före driftsättning har QA-fliken aldrig sett dem. Strukturfelen lämnar via bakdörren.
Om du har ett dev-only CLI: din CI validerar filsyntax. Den validerar inte variabelbevarende, taggintegritet eller ordlistekonsistens. Dessa kontroller kräver medvetenhet om stränginnehållet, inte bara formatet.
Hur en systematisk lokaliseringsprocess ser ut
En systematisk process kör de fem automatiserade kontrollerna vid två tillfällen, och lägger sedan mänsklig granskning ovanpå:
Kör de fem utvärderarna kontinuerligt när texter uppdateras. Kontrollerna körs automatiskt på två ställen. När AI-översättningar genereras kör Prismys AI-översättningsmotor stavningskontroll, variabelbevarende, HTML-integritet, ordlistekonsistens och längdkontroller vid genereringen: strukturfel hamnar aldrig i översättningsfilerna. Inline under redigering, i Prismys webbapp och i Chrome-tillägget, ser redaktörer problem flaggade i realtid innan de bekräftar en ändring. Fixa det innan lansering, inte efter.
Kör utvärderarna en gång på dina befintliga texter när du ställer in Prismy för första gången. De flesta team har översättningsfiler byggda under år: strängar skrivna av människor, kopierade mellan verktyg, redigerade utan utvärderare som bevakar. Det backlogen har tyst trasiga variabler, ordlistetermer applicerade inkonsekvent och längder som flödar över på skärmar ingen kontrollerat. En engångsrevision exponerar allt detta innan du går live.
Prismys utvärderare hanterar båda tillfällena automatiskt: stavningskontroll, variabelkontroll, HTML-integritet, ordlistematchning och längdsaldo körs på varje Git-nativ pull request och inline i redigeraren. För AI-översättningskvaliteten som driver processen uppströms, se hela guiden.
-
StavningskontrollAutomatiserbarVälj tre översättningsnycklar från dina mest använda locales och kör dem genom ett stavningskontrollverktyg. Stavfel och grammatikfel som granskare läser förbi dyker upp direkt.
-
VariabelbevarendeAutomatiserbarSök igenom dina översatta filer efter
{,%eller{{som finns i källan men inte i översättningen. Om du hittar ett har din QA-process inte fångat det. -
HTML-taggintegritetAutomatiserbarKör en taggbalansekontroll på översatta strängar som innehåller HTML. En öppen
<strong>eller<a>i produktion sprider fetstil eller länkstilar över ett stycke. -
OrdlistekonsistensAutomatiserbarVälj tre viktiga produkttermer (din primära CTA, ditt produktnamn, ett funktionsnamn). Kontrollera om de översätts på samma sätt i varje sträng på varje språk. Om inte behöver du en ordlistekontroll i din utvärderare.
-
Längd och overflowAutomatiserbarLadda din produkt på tyska eller ett annat språk med lång expansion. Kontrollera varje knapp och etikett för trunkering. Om något kapas kontrolleras inte dina teckensaldon vid QA-tillfället.
FAQ
Vad är skillnaden mellan lokaliseringsQA och översättningsgranskning?
Översättningsgranskning är en mänsklig kvalitetskontroll: ton, noggrannhet, flyt. Lokaliseringskvalitetssäkring inkluderar det, plus automatiserade mekaniska kontroller: stavning, variabler, HTML, ordlista, längd. QA ska köras före mänsklig granskning, inte istället för den. Det automatiserade lagret rensar strukturfelen så att den mänskliga granskaren kan fokusera på bedömning.
Hur testar du lokalisering innan release?
Fyra steg: automatiserade utvärderare på varje pull request (stavning, variabler, HTML, ordlista, längd), kontextuell mänsklig granskning i den körande appen, ett lätt release-smoktest på ett språk, och en kvartalsvis ordlistegranskning för att hålla de automatiserade kontrollerna aktuella med din produktterminologi. En solid översättnings-QA-process inkluderar även lokaliseringstester i verkliga enhets- och skärmkontexter för att fånga overflow- och renderingsproblem som strängnivåkontroller missar.
Vad orsakar fel i översättningskvalitetssäkringen i produktion?
Vanligtvis inte översättaren. Vanligtvis processen. Saknade variabler glider igenom när översättare arbetar i klartext utan utvärderare som bevakar. Ordlisteglidning sker när ingen kontroll upprätthåller terminologin. Längdoverflow sker när ingen testar renderade strängar i ett verkligt UI. De flesta produktionsöversättningsfel är strukturella, inte språkliga, och de flesta strukturfel är automatiserbara.
Kan automatiserade verktyg ersätta mänsklig översättningsgranskning?
För strukturfel (stavning, variabler, HTML, ordlista, längd): ja, och de gör det mer konsekvent och snabbare än en människa. För språklig bedömning (ton, kulturell passform, nyans): nej. En komplett lokaliseringskvalitetsprocess använder båda: automatiserade kontroller rensar bort mekaniska fel, mänsklig granskning fångar de språkliga. Den automatiserade detekteringsgraden på 70-94 % lämnar 6-30 % för mänskliga granskare att fokusera på.
Missa inte våra branschinsikter!
Få de senaste insikterna om lokalisering, AI-översättningar och produktuppdateringar direkt till din inkorg.
Ingen skräppost, avsluta prenumerationen när som helst. Vi respekterar din integritet.

Gå globalt, på ett enkelt och kraftfullt sätt.

© 2026 Prismy. Alla rättigheter förbehållna.