21/05/2026 · Industry
Controlo de qualidade da localização para equipas SaaS: o que verificar antes de publicar
73% das equipas SaaS descobrem erros por relatórios de utilizadores, não pela QA. Aprenda como o controlo de qualidade da localização deteta variáveis incorretas, HTML, glossário e comprimento.

Um revisor nativo edita uma cadeia de caracteres traduzida por IA e muda o nome de
{userName}para{nomeUtilizador}. A variável deixa de ser resolvida. A etiqueta passa a mostrar{nomeUtilizador}em produção para todos os utilizadores franceses. A revisão manual aprovou-a: o revisor estava a ler para compreender o significado. Uma verificação automatizada tê-la-ia detetado em menos de um segundo.
O que significa realmente o controlo de qualidade da localização
O controlo de qualidade da localização é o processo de verificar que as traduções estão corretas antes de chegarem aos utilizadores. Abrange tanto a garantia de qualidade da tradução (o significado é preciso?) como a integridade estrutural (as variáveis, as etiquetas e os termos do glossário estão intactos?). São duas tarefas separadas com duas ferramentas diferentes: verificações automatizadas para erros estruturais e revisão humana para julgamento linguístico.
A maioria das equipas confunde-as. Enviam cadeias de caracteres a um membro bilingue da equipa e consideram o trabalho concluído. O revisor deteta problemas de tom. Não deteta uma variável em falta porque está a ler para compreender o significado, não a executar uma correspondência de padrões.
Os números confirmam-no. Um inquérito a programadores em 2026 realizado a 1.000 equipas de engenharia e produto revelou que 73% descobre erros de tradução em produção através de relatórios de utilizadores (IntlPull, State of i18n 2026). Não pela QA. Não por testes. Por reclamações de utilizadores. O mesmo inquérito revelou que 52% não tem nenhum processo de QA sistemático para além de verificações manuais pontuais.
As verificações manuais pontuais não são um processo de QA. São uma lotaria.
Os erros estruturais são os que vale a pena automatizar. É assim que se apresentam.
Os cinco tipos de verificações de QA de localização
Cada cadeia de caracteres de tradução passa por cinco verificações automatizadas antes de um revisor humano a ver. Cada uma deteta uma classe de falhas que a revisão manual erra sistematicamente.
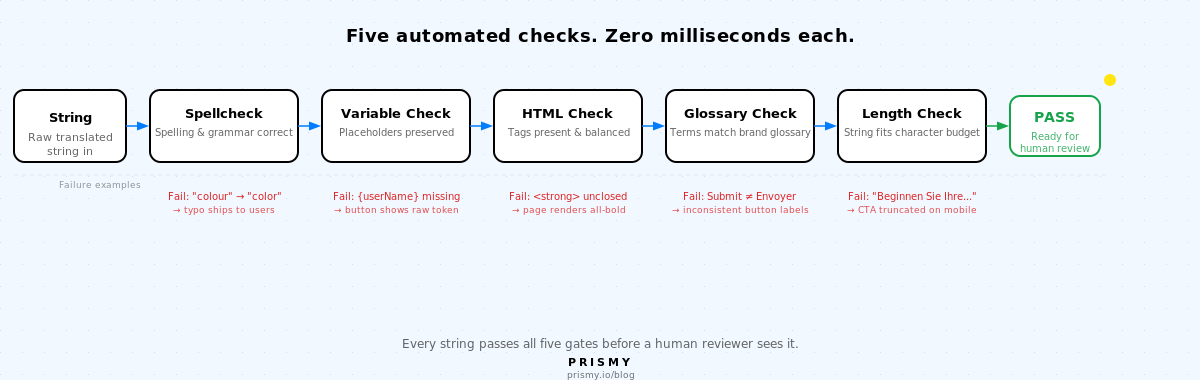
1. Verificação ortográfica
Cada chave de tradução deve estar isenta de erros ortográficos e gramaticais.
O modo de falha: uma cadeia de caracteres traduzida por IA ou uma edição humana introduz um erro tipográfico, uma forma verbal incorreta ou um erro gramatical que passa despercebido porque ninguém o está explicitamente a procurar. A revisão manual deteta muitos destes, mas os revisores que leem para compreender o significado perdem erros subtis, especialmente em línguas em que não são completamente fluentes.
A verificação ortográfica automatizada corre em cada chave de tradução em cada locale antes de a cadeia chegar a um revisor. Sinaliza erros ortográficos e problemas gramaticais básicos em menos de um milissegundo, em escala, em todas as línguas em paralelo.
2. Preservação de variáveis
Cada marcador de posição de interpolação na cadeia de caracteres de origem deve aparecer na cadeia traduzida com o formato correto.
O modo de falha: um revisor nativo edita uma cadeia de caracteres traduzida por IA e muda o nome da variável: {userName} torna-se {nomeUtilizador}, ou elimina-a completamente ao reformular. A variável deixa de ser resolvida. Em produção, os utilizadores veem o marcador de posição sem formatação em vez do seu nome. A tradução por IA trata isto corretamente; o erro é introduzido quando um humano edita o resultado sem perceber que a variável é essencial.
Isto é automatizável com uma simples correspondência de padrões. A verificação corre em menos de um milissegundo. O mesmo inquérito revelou que 61% das equipas já experimentou variáveis de marcador de posição quebradas em produção. Cada uma dessas falhas passou por uma revisão humana.
3. Integridade de HTML e de etiquetas
Cada etiqueta HTML na cadeia de caracteres de origem deve estar presente e em equilíbrio na tradução.
O modo de falha: um tradutor trabalha em modo de texto simples, ou um sistema de tradução automática remove uma etiqueta de fecho ao reconstruir a cadeia. A origem diz Your subscription is <strong>active</strong>. A tradução diz A sua subscrição está <strong>ativa. Falta </strong>. O resto da página é renderizado a negrito.
As verificações automatizadas de equilíbrio de etiquetas detetam isto. De acordo com o mesmo inquérito, 41% das equipas já publicou traduções quebradas que danificaram o layout da interface. A perda de etiquetas HTML é uma das principais causas.
4. Consistência do glossário
Cada termo no glossário da marca deve aparecer com a sua tradução correta em cada língua, de forma consistente em todas as cadeias de caracteres.
Sem uma verificação do glossário, os tradutores tomam decisões independentes ao nível das palavras. «Submit» torna-se «Enviar» numa cadeia e «Submeter» noutra. «Free trial» torna-se «período de teste gratuito» na página de preços e «experiência gratuita» no fluxo de integração. Os utilizadores notam-no. Os tickets de suporte mencionam «o botão confuso».
58% das equipas reporta terminologia incorreta e termos inconsistentes como tipo de erro de produção. A solução não são tradutores melhores. É um glossário que o avaliador verifica em cada cadeia.
O verdadeiro trabalho faz-se no glossário. Precisamos de garantir que as traduções dos termos-chave estão corretas na nova língua. É aí que passamos mais tempo.Alexis Toyane, Product Lead na Figures
A Figures passou de duas línguas para nove. O glossário não foi o custo. Foi o alicerce. Veja como o conseguiram: A Figures escalou para nove línguas.
5. Comprimento e sobreposição
A cadeia traduzida deve caber no elemento de interface que irá ocupar. O texto em alemão é 30-40% mais longo do que em inglês. O japonês pode ser mais curto, mas requer regras de altura de linha diferentes.
Ninguém verifica o comprimento até a cadeia estar na aplicação em execução. O TMS mostra a cadeia sem formatação, não o botão renderizado. Um call-to-action em alemão que deveria dizer «Start your free trial» torna-se «Beginnen Sie Ihre kostenlose...» e fica cortado na margem do botão. O CTA principal é invisível num dos seus mercados principais.
67% das equipas já experimentou sobreposição de texto e truncagem em produção. Definir orçamentos de caracteres por cadeia e verificá-los ao nível da cadeia deteta a cauda longa antes da renderização.
Por que a revisão manual erra os erros estruturais
Um revisor humano lê para compreender o significado. Vai detetar uma discrepância de tom, um deslize cultural, uma frase que soa artificial em português. Não vai detetar {userName} sem resolução na cadeia porque inconscientemente lê-o como um valor preenchido.
Os revisores também trabalham em escala: 20-50 cadeias por hora é um ritmo realista para revisão cuidadosa. Uma versão de 50 cadeias em cinco línguas significa 250 revisões de cadeias. As verificações estruturais correm nas mesmas 250 cadeias em milissegundos.
Os dados do inquérito Common Sense Advisory de 2025 são diretos: a QA automatizada deteta 70-80% de todos os problemas de tradução, subindo para 90-94% em equipas com gestão rigorosa do glossário. Os restantes 6-30% são linguísticos e culturais, requerendo julgamento humano. Essa é a divisão do trabalho.
O argumento de custo fecha o raciocínio. Corrigir um erro de tradução depois de chegar à produção custa 8-12 vezes mais do que detetá-lo durante a tradução (Nimdzi). Para uma equipa com cinco línguas e dois lançamentos por mês, esse cálculo muda rapidamente.
Há três pontos de partida comuns:
Se está num processo manual: o seu revisor bilingue deteta os 20% linguísticos. Os 80% estruturais são publicados. A variável que o seu revisor não notou está agora à frente de 2.000 utilizadores alemães.
Se está num TMS empresarial: o seu separador de QA existe, mas corre dentro de uma plataforma. Se as cadeias são copiadas e coladas fora do TMS antes da implementação, o separador de QA nunca as viu. Os erros estruturais saem pela porta do lado.
Se está num CLI apenas para programadores: o seu CI valida a sintaxe dos ficheiros. Não valida a preservação de variáveis, a integridade de etiquetas ou a consistência do glossário. Essas verificações requerem conhecimento do conteúdo da cadeia, não apenas do seu formato.
Como se parece um processo sistemático de QA de localização
Um processo sistemático corre as cinco verificações automatizadas em dois momentos e depois adiciona revisão humana:
Corra os cinco avaliadores continuamente à medida que os textos são atualizados. As verificações correm automaticamente em dois sítios. Quando as traduções de IA são geradas, o motor de tradução de IA da Prismy corre verificação ortográfica, preservação de variáveis, integridade HTML, consistência do glossário e verificações de comprimento no momento da geração: os erros estruturais nunca entram nos ficheiros de tradução. Inline durante a edição, na aplicação web da Prismy e na extensão para Chrome, os editores veem os problemas sinalizados em tempo real antes de confirmarem uma alteração. Corrija-o antes de publicar, não depois.
Corra os avaliadores uma vez nos seus textos existentes quando configurar a Prismy pela primeira vez. A maioria das equipas tem ficheiros de tradução construídos ao longo de anos: cadeias escritas por humanos, copiadas entre ferramentas, editadas sem avaliadores a supervisionar. Esse backlog tem variáveis silenciosamente quebradas, termos do glossário aplicados de forma inconsistente e comprimentos que transbordam em ecrãs que ninguém verificou. Uma passagem de auditoria única faz emergir tudo isso antes de ir a produção.
Os avaliadores da Prismy tratam automaticamente ambos os momentos: verificação ortográfica, verificação de variáveis, integridade HTML, correspondência do glossário e orçamento de comprimento correm em cada pull request Git-nativo e inline no editor. Para a qualidade da tradução de IA que alimenta o processo a montante, consulte o guia completo.
-
Verificação ortográficaAutomatizávelEscolha três chaves de tradução dos seus locales mais utilizados e execute-os num instrumento de verificação ortográfica. Os erros tipográficos e os deslizes gramaticais que os revisores passam ao lado aparecem imediatamente.
-
Preservação de variáveisAutomatizávelProcure nos seus ficheiros traduzidos por
{,%ou{{que aparece na origem mas não na tradução. Se encontrar um, o seu processo de QA não o detetou. -
Integridade de etiquetas HTMLAutomatizávelExecute uma verificação de equilíbrio de etiquetas em quaisquer cadeias traduzidas que contenham HTML. Um
<strong>ou<a>não fechado em produção vai propagar o estilo negrito ou de ligação por um parágrafo. -
Consistência do glossárioAutomatizávelEscolha três termos-chave do produto (o seu CTA principal, o nome do seu produto, um nome de funcionalidade). Verifique se são traduzidos da mesma forma em todas as cadeias em todas as línguas. Se não, precisa de uma verificação do glossário no seu avaliador.
-
Comprimento e sobreposiçãoAutomatizávelCarregue o seu produto em alemão ou noutra língua de expansão longa. Verifique cada botão e etiqueta para truncagem. Se algo for cortado, os seus orçamentos de caracteres não são verificados no momento de QA.
FAQ
Qual é a diferença entre QA de localização e revisão de tradução?
A revisão de tradução é uma verificação humana de qualidade: tom, precisão, fluência. O controlo de qualidade da localização inclui isso mais verificações mecânicas automatizadas: ortografia, variáveis, HTML, glossário, comprimento. A QA deve correr antes da revisão humana, não em vez dela. A camada automatizada elimina os erros estruturais para que o revisor humano se concentre no julgamento.
Como se testa a localização antes do lançamento?
Quatro passos: avaliadores automatizados em cada pull request (ortografia, variáveis, HTML, glossário, comprimento), revisão humana em contexto na aplicação em execução, um teste de fumo de lançamento ligeiro numa língua, e uma auditoria trimestral do glossário para manter as verificações automatizadas atualizadas com a terminologia do seu produto. Um processo sólido de QA de tradução também inclui testes de localização em contextos reais de dispositivos e ecrãs para detetar problemas de sobreposição e renderização que as verificações ao nível da cadeia não detetam.
O que causa falhas na garantia de qualidade da tradução em produção?
Geralmente não é o tradutor. Geralmente é o processo. Variáveis em falta passam quando os tradutores trabalham em texto simples sem avaliadores a supervisionar. A deriva do glossário acontece quando nenhuma verificação impõe a terminologia. A sobreposição de comprimento acontece quando ninguém testa as cadeias renderizadas numa interface real. A maioria dos erros de tradução em produção são estruturais, não linguísticos, e a maioria dos erros estruturais são automatizáveis.
As ferramentas automatizadas podem substituir a revisão humana de tradução?
Para erros estruturais (ortografia, variáveis, HTML, glossário, comprimento): sim, e fazem-no de forma mais consistente e rápida do que um humano. Para julgamento linguístico (tom, adequação cultural, nuance): não. Um processo completo de QA de localização usa ambos: as verificações automatizadas eliminam as falhas mecânicas, a revisão humana deteta as linguísticas. A taxa de deteção automatizada de 70-94% deixa 6-30% para os revisores humanos se concentrarem.
Não perca as nossas análises do setor!
Receba as últimas novidades sobre localização, traduções com IA e atualizações de produtos diretamente na sua caixa de entrada.
Sem spam, cancele a subscrição a qualquer momento. Respeitamos a sua privacidade.

Ir global, de forma simples e poderosa.

© 2026 Prismy. Todos os direitos reservados.