21-05-2026 · Industry
Lokalisatie kwaliteitscontrole voor SaaS-teams: wat je checkt voor je live gaat
73% van de SaaS-teams ontdekt fouten via gebruikersmeldingen, niet via QA. Leer hoe lokalisatie kwaliteitscontrole gebroken variabelen, HTML, woordenlijst en lengte detecteert.

Een native reviewer bewerkt een AI-vertaalde string en hernoemt
{userName}naar{gebruikersNaam}. De variabele wordt niet meer opgelost. Het label toont nu{gebruikersNaam}in productie voor elke Franse gebruiker. Handmatige review keurde het goed: de reviewer las op betekenis. Een geautomatiseerde check had het in minder dan een seconde gevonden.
Wat lokalisatie kwaliteitscontrole echt betekent
Lokalisatie kwaliteitscontrole is het proces om te verifiëren dat vertalingen correct zijn voordat ze gebruikers bereiken. Het omvat zowel vertaalkwaliteitscontrole (is de betekenis accuraat?) als structurele integriteit (zijn variabelen, tags en termen uit de woordenlijst intact?). Dat zijn twee aparte taken met twee verschillende tools: geautomatiseerde checks voor structurele fouten en menselijke review voor taalkundig oordeel.
De meeste teams verwarren deze twee. Ze sturen strings naar een tweetalig teamlid en beschouwen het als gedaan. De reviewer vangt toonproblemen op. Hij vangt geen ontbrekende variabele op, want hij leest op betekenis en voert geen patroonvergelijking uit.
De cijfers bevestigen dit. Een ontwikkelaarsonderzoek uit 2026 onder 1.000 engineering- en productteams toonde aan dat 73% vertaalfouten in productie ontdekt via gebruikersmeldingen (IntlPull, State of i18n 2026). Niet via QA. Niet via tests. Via gebruikersklachten. Uit hetzelfde onderzoek bleek dat 52% geen systematisch QA-proces heeft buiten handmatige steekproeven.
Handmatige steekproeven zijn geen QA-proces. Het is een loterij.
Structurele fouten zijn de fouten die de moeite waard zijn om te automatiseren. Zo zien ze eruit.
De vijf typen lokalisatie-QA-checks
Elke vertaalstring doorloopt vijf geautomatiseerde checks voordat een menselijke reviewer hem ziet. Elke check detecteert een foutklasse die handmatige review consequent mist.
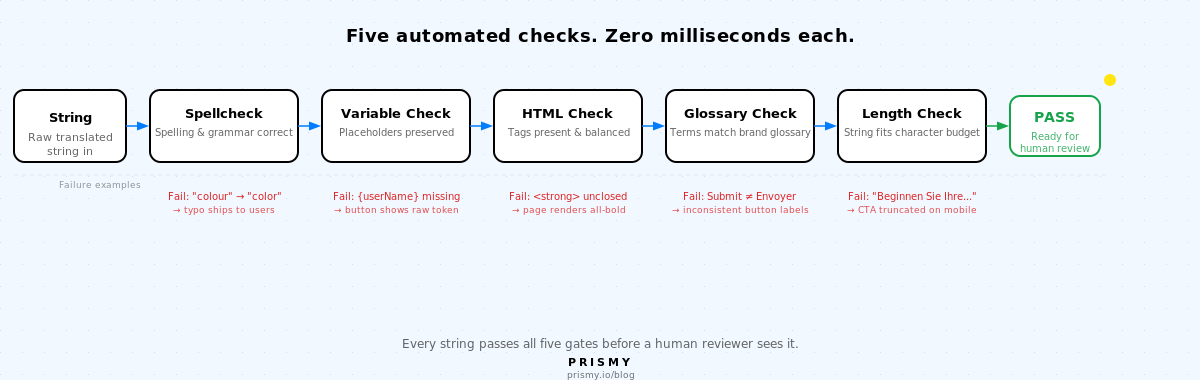
1. Spellingcheck
Elke vertaalsleutel moet vrij zijn van spel- en grammaticafouten.
De foutmodus: een AI-vertaalde string of een menselijke bewerking introduceert een typefout, een verkeerde werkwoordsvorm of een grammaticafout die onopgemerkt blijft omdat niemand er expliciet naar kijkt. Handmatige review vangt er veel op, maar reviewers die op betekenis lezen missen subtiele fouten, met name in talen waar ze niet volledig vloeiend in zijn.
Geautomatiseerde spellingcheck loopt over elke vertaalsleutel in elke locale voordat de string een reviewer bereikt. Het markeert spelfouten en basale grammaticaproblemen in minder dan een milliseconde, op schaal, in alle talen parallel.
2. Variabelebehoud
Elke interpolatieplaatshouder in de bronstring moet verschijnen in de vertaalde string, met het juiste formaat.
De foutmodus: een native reviewer bewerkt een AI-vertaalde string en hernoemt de variabele: {userName} wordt {gebruikersNaam}, of hij laat hem volledig weg bij herformulering. De variabele wordt niet meer opgelost. In productie zien gebruikers de onbewerkte plaatshouder in plaats van hun naam. AI-vertaling verwerkt dit correct; de fout wordt geïntroduceerd wanneer een mens de output bewerkt zonder te beseffen dat de variabele essentieel is.
Dit is automatiseerbaar met een eenvoudige patroonvergelijking. De check loopt in minder dan een milliseconde. Uit hetzelfde onderzoek bleek dat 61% van de teams gebroken plaatshouders in productie heeft meegemaakt. Elk van die mislukkingen heeft een menselijke review doorstaan.
3. HTML- en tag-integriteit
Elke HTML-tag in de bronstring moet aanwezig en in balans zijn in de vertaling.
De foutmodus: een vertaler werkt in de platte-tekstmodus, of een machine-vertaalsysteem verwijdert een sluitende tag bij het reconstrueren van de string. De bron zegt Your subscription is <strong>active</strong>. De vertaling zegt Je abonnement is <strong>actief. </strong> ontbreekt. De rest van de pagina rendert vet.
Geautomatiseerde tag-balancechecks detecteren dit. Volgens hetzelfde onderzoek heeft 41% van de teams gebroken vertalingen verzonden die de UI-indeling beschadigden. HTML-tagverlies is een van de topooorzaken.
4. Woordenlijstconsistentie
Elke term in de merkwoordenlijst moet verschijnen met zijn correcte vertaling in elke taal, consistent over alle strings.
Zonder een woordenlijstcheck nemen vertalers onafhankelijke beslissingen op woordniveau. «Submit» wordt «Versturen» in de ene string en «Indienen» in een andere. «Free trial» wordt «gratis proefperiode» op de prijzenpagina en «gratis proberen» in de onboarding-flow. Gebruikers merken dit. Supporttickets noemen «de verwarrende knop».
58% van de teams meldt onjuiste terminologie en inconsistente termen als productiefouttype. De oplossing zijn niet betere vertalers. Het is een woordenlijst die de evaluator controleert op elke string.
Het echte werk wordt gedaan op de woordenlijst. We moeten zorgen dat vertalingen van sleuteltermen correct zijn in de nieuwe taal. Daar besteden we de meeste tijd aan.Alexis Toyane, Product Lead bij Figures
Figures schaalde van twee talen naar negen. De woordenlijst was niet de overhead. Het was het fundament. Ontdek hoe ze dat bereikten: Figures schaalde naar negen talen.
5. Lengte en overflow
De vertaalde string moet passen in het UI-element dat hij zal bezetten. Duits tekst is 30-40% langer dan Engels. Japans kan korter zijn maar vereist andere regelhoogteregels.
Niemand controleert lengte totdat de string in de actieve app zit. Het TMS toont de ruwe string, niet de gerenderde knop. Een Duits call-to-action dat «Start your free trial» moet zeggen, wordt «Beginnen Sie Ihre kostenlose...» en wordt afgekapt aan de rand van de knop. De primaire CTA is onzichtbaar in een van je topmarkten.
67% van de teams heeft tekstoverflow en afkapping in productie meegemaakt. Tekenbudgetten per string instellen en deze controleren op stringniveau vangt de lange staart op vóór het renderen.
Waarom handmatige review structurele fouten mist
Een menselijke reviewer leest op betekenis. Hij vangt een toonmismatch op, een cultureel uitglijden, een zin die houterig klinkt in het Portugees. Hij vangt {userName} niet op dat onopgelost in de string zit, want hij leest het onbewust als een ingevulde waarde.
Reviewers werken ook op schaal: 20-50 strings per uur is een realistisch tempo voor zorgvuldige review. Een release van 50 strings over vijf talen betekent 250 string-reviews. Structurele checks lopen over dezelfde 250 strings in milliseconden.
De gegevens uit het Common Sense Advisory-onderzoek van 2025 zijn direct: geautomatiseerde QA vangt 70-80% van alle vertaalproblemen op, oplopend tot 90-94% voor teams met strikte woordenlijstbeheer. De resterende 6-30% is taalkundig en cultureel en vereist menselijk oordeel. Dat is de taakverdeling.
De kostenberekening sluit het af. Een vertaalfout corrigeren nadat die productie bereikt, kost 8-12 keer meer dan het opvangen tijdens vertaling (Nimdzi). Voor een team met vijf talen en twee releases per maand verandert die berekening snel.
Je hebt drie veelvoorkomende startpunten:
Als je een handmatig proces hebt: je tweetalige reviewer vangt de taalkundige 20% op. De structurele 80% wordt verzonden. De variabele die je reviewer niet opmerkte, staat nu voor 2.000 Duitse gebruikers.
Als je een enterprise TMS hebt: je QA-tab bestaat, maar loopt binnen een platform. Als strings vóór implementatie uit het TMS worden gekopieerd en geplakt, heeft de QA-tab ze nooit gezien. De structurele fouten verlaten via de achterdeur.
Als je een dev-only CLI hebt: je CI valideert bestandssyntax. Het valideert geen variabelebehoud, tag-integriteit of woordenlijstconsistentie. Die checks vereisen bewustzijn van de stringinhoud, niet alleen het formaat.
Hoe een systematisch lokalisatie-QA-proces eruitziet
Een systematisch proces voert de vijf geautomatiseerde checks op twee momenten uit en voegt dan menselijke review toe:
Voer de vijf evaluatoren continu uit terwijl teksten worden bijgewerkt. De checks lopen automatisch op twee plaatsen. Wanneer AI-vertalingen worden gegenereerd, voert Prismy's AI-vertaalmotor spellingcheck, variabelebehoud, HTML-integriteit, woordenlijstconsistentie en lengtechecks uit op het moment van genereren: structurele fouten komen nooit in de vertaalbestanden terecht. Inline tijdens bewerken, in de Prismy-webapp en in de Chrome-extensie, zien editors problemen in real time gemarkeerd voordat ze een wijziging vastleggen. Los het op vóór verzending, niet erna.
Voer de evaluatoren eenmalig uit op je bestaande teksten wanneer je Prismy voor het eerst instelt. De meeste teams hebben vertaalbestanden die over jaren zijn opgebouwd: strings geschreven door mensen, gekopieerd tussen tools, bewerkt zonder evaluatoren die toekijken. Dat backlog heeft stil gebroken variabelen, inconsistent toegepaste woordenlijsttermen en lengtes die overflowden op schermen die niemand controleerde. Een eenmalige auditrun legt dit allemaal bloot vóór je live gaat.
Prismy's evaluatoren verwerken beide momenten automatisch: spellingcheck, variabelcheck, HTML-integriteit, woordenlijstmatching en lengte-budget lopen op elke Git-native pull request en inline in de editor. Voor de AI-vertaalkwaliteit die het proces upstream voedt, zie de volledige gids.
-
SpellingcheckAutomatiseerbaarKies drie vertaalsleutels uit je meest gebruikte locales en voer ze door een spellingchecktool. Typefouten en grammaticale slipjes die reviewers voorbijlezen, verschijnen direct.
-
VariabelebehoudAutomatiseerbaarDoorzoek je vertaalde bestanden op
{,%of{{dat in de bron verschijnt maar niet in de vertaling. Als je er een vindt, heeft je QA-proces het niet gevangen. -
HTML-tag-integriteitAutomatiseerbaarVoer een tag-balancecheck uit op vertaalde strings die HTML bevatten. Een niet-gesloten
<strong>of<a>in productie zal vet- of linkstijl over een alinea cascaderen. -
WoordenlijstconsistentieAutomatiseerbaarKies drie belangrijke producttermen (je primaire CTA, je productnaam, een functienaam). Controleer of ze op dezelfde manier worden vertaald in elke string over elke taal. Als dat niet het geval is, heb je een woordenlijstcheck nodig in je evaluator.
-
Lengte en overflowAutomatiseerbaarLaad je product in het Duits of een andere taal met langere expansie. Controleer elke knop en elk label op afkapping. Als iets wordt afgesneden, worden je tekenbudgetten niet gecontroleerd op het moment van QA.
FAQ
Wat is het verschil tussen lokalisatie-QA en vertaalreview?
Vertaalreview is een menselijke kwaliteitscontrole: toon, nauwkeurigheid, vloeiendheid. Lokalisatie kwaliteitscontrole omvat dat plus geautomatiseerde mechanische checks: spelling, variabelen, HTML, woordenlijst, lengte. QA moet vóór menselijke review worden uitgevoerd, niet in plaats daarvan. De geautomatiseerde laag verwijdert structurele fouten zodat de menselijke reviewer zich kan concentreren op oordeel.
Hoe test je lokalisatie vóór een release?
Vier stappen: geautomatiseerde evaluatoren op elke pull request (spelling, variabelen, HTML, woordenlijst, lengte), in-context menselijke review in de actieve app, een lichte release smoke test over één taal, en een kwartaalsgewijze woordenlijstaudit om de geautomatiseerde checks actueel te houden met je productterminologie. Een solide vertaal-QA-proces omvat ook lokalisatietests in echte apparaat- en schermcontexten om overflow- en renderingproblemen te detecteren die string-level checks missen.
Wat veroorzaakt mislukkingen in vertaalkwaliteitscontrole in productie?
Doorgaans niet de vertaler. Doorgaans het proces. Ontbrekende variabelen slippen door wanneer vertalers in platte tekst werken zonder evaluatoren die toekijken. Woordenlijstdrift ontstaat wanneer geen check terminologie afdwingt. Lengteoverflow ontstaat wanneer niemand gerenderde strings in een echte UI test. De meeste productievertaalfouten zijn structureel, niet taalkundig, en de meeste structurele fouten zijn automatiseerbaar.
Kunnen geautomatiseerde tools menselijke vertaalreview vervangen?
Voor structurele fouten (spelling, variabelen, HTML, woordenlijst, lengte): ja, en ze doen het consistenter en sneller dan een mens. Voor taalkundig oordeel (toon, culturele fit, nuance): nee. Een compleet lokalisatie-QA-proces gebruikt beide: geautomatiseerde checks verwijderen mechanische mislukkingen, menselijke review vangt de taalkundige op. Het geautomatiseerde detectiepercentage van 70-94% laat 6-30% over voor menselijke reviewers.
Mis onze branche-inzichten niet!
Ontvang de laatste inzichten over lokalisatie, AI-vertalingen en productupdates in je inbox.
Geen spam, op elk moment afmelden. We respecteren je privacy.

Ga wereldwijd, op een eenvoudige en krachtige manier.

© 2026 Prismy. Alle rechten voorbehouden.