2026年5月21日 · Industry
SaaSチームの翻訳品質管理:リリース前に確認すべきこと
SaaSチームの73%がQAではなくユーザー報告でエラーを発見しています。翻訳品質管理が壊れた変数、HTML、用語集、文字数の問題を検出する方法を解説します。

ネイティブスピーカーのレビュアーがAI翻訳された文字列を編集し、
{userName}を{ユーザー名}に変更しました。変数はもはや解決されません。フランス語ユーザーのすべてに対して、本番環境でラベルに{ユーザー名}が表示されるようになりました。手動レビューはこれを承認していました。レビュアーは意味を読んでいたからです。自動チェックであれば1秒以内に検出できたはずです。
ローカリゼーション品質保証が実際に意味すること
ローカリゼーション品質保証とは、翻訳がユーザーに届く前に正確であることを検証するプロセスです。翻訳品質管理(意味は正確か?)と構造的整合性(変数、タグ、用語集の用語は損なわれていないか?)の両方をカバーします。これは2つの異なるツールを必要とする2つの別々の作業です。構造的エラーには自動チェック、言語的判断には人間によるレビューです。
ほとんどのチームはこれらを混同しています。バイリンガルのチームメンバーに文字列を送り、完了とみなします。レビュアーはトーンの問題を検出します。しかし、意味を読んでいるため、パターンマッチングを実行しているわけではなく、変数の欠落を検出しません。
数字がこれを裏付けています。1,000のエンジニアリングおよび製品チームを対象とした2026年の開発者調査によると、73%が翻訳エラーをQAやテストではなく、ユーザー報告によって本番環境で発見しています(IntlPull, State of i18n 2026)。同調査では、52%が手動スポットチェック以外の体系的なQAプロセスを持っていないことも明らかになりました。
手動スポットチェックはQAプロセスではありません。それは宝くじです。
自動化する価値があるのは構造的エラーです。以下にその例を示します。
ローカリゼーションQAチェックの5つのタイプ
すべての翻訳文字列は、人間のレビュアーが確認する前に5つの自動チェックを通過します。それぞれが、手動レビューが常に見逃す障害クラスを検出します。
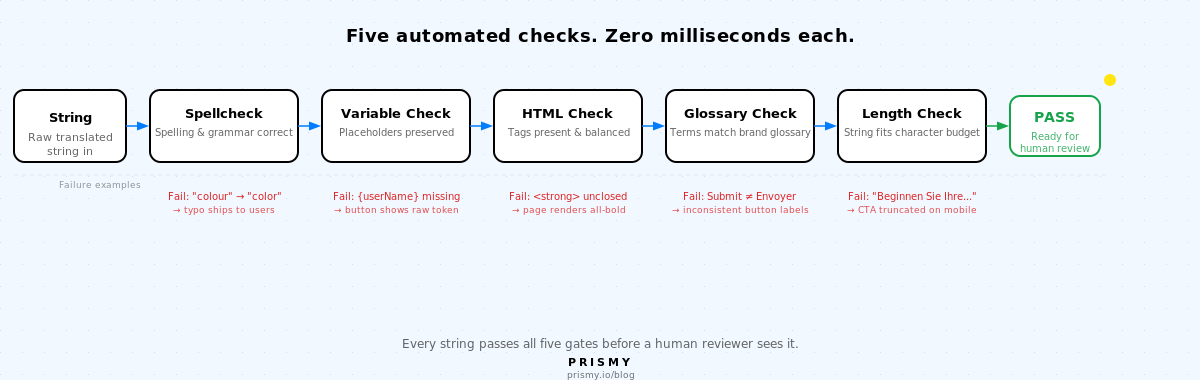
1. スペルチェック
すべての翻訳キーはスペルと文法のエラーがない状態である必要があります。
失敗のパターン:AI翻訳された文字列や人間による編集で、タイポ、間違った動詞の形、または文法のミスが発生し、誰も明示的に探していないため気づかれません。手動レビューはこれらの多くを検出しますが、意味を読んでいるレビュアーは特に完全に流暢でない言語において微妙なエラーを見逃します。
自動スペルチェックは、文字列がレビュアーに届く前に各ロケールのすべての翻訳キーに対して実行されます。1ミリ秒未満でスペルエラーと基本的な文法の問題をフラグし、すべての言語を並行してスケールで処理します。
2. 変数保持
ソース文字列内のすべての補間プレースホルダーは、正しい形式で翻訳済み文字列に表示される必要があります。
失敗のパターン:ネイティブスピーカーのレビュアーがAI翻訳された文字列を編集し、変数を変更します。{userName}が{ユーザー名}になったり、言い換えの際に完全に削除されたりします。変数はもはや解決されません。本番環境では、ユーザーは名前の代わりに生のプレースホルダーを見ます。AI翻訳はこれを正しく処理します。エラーは、変数が重要であることに気づかずに人間が出力を編集するときに発生します。
これは単純なパターンマッチングで自動化できます。チェックは1ミリ秒未満で実行されます。同調査では、61%のチームが本番環境でプレースホルダー変数の破損を経験したことも明らかになりました。これらの失敗のすべてが人間のレビューを通過しています。
3. HTMLとタグの整合性
ソース文字列内のすべてのHTMLタグは、翻訳に存在し、バランスが取れている必要があります。
失敗のパターン:翻訳者がプレーンテキストモードで作業するか、機械翻訳システムが文字列を再構築する際に閉じタグを削除します。ソースはYour subscription is <strong>active</strong>と表示されます。翻訳はご契約は<strong>有効と表示されます。</strong>が欠落しています。ページの残りの部分が太字でレンダリングされます。
自動タグバランスチェックはこれを検出します。同調査によると、41%のチームがUIレイアウトを壊した翻訳を公開しています。HTMLタグの欠落は主要な原因の1つです。
4. 用語集の一貫性
ブランド用語集内のすべての用語は、各言語で正しい翻訳が表示され、すべての文字列にわたって一貫している必要があります。
用語集チェックがないと、翻訳者は単語レベルで独立した判断を下します。「Submit」がある文字列では「送信」になり、別の文字列では「提出」になります。「Free trial」が料金ページでは「無料トライアル」になり、オンボーディングフローでは「無料体験」になります。ユーザーはこれに気づきます。サポートチケットには「わかりにくいボタン」と書かれます。
58%のチームが、不正確な用語と一貫性のない用語を本番エラーのタイプとして報告しています。解決策はより良い翻訳者ではありません。評価者がすべての文字列でチェックする用語集です。
本当の作業は用語集で行われます。新しい言語で重要な用語の翻訳が正確であることを確認する必要があります。そこで最も多くの時間を費やしています。Alexis Toyane、FiguresのProduct Lead
Figuresは2言語から9言語に拡張しました。用語集はオーバーヘッドではありませんでした。それは基盤でした。どのように達成したかをご覧ください:Figuresが9言語に拡張した方法。
5. 文字数とオーバーフロー
翻訳された文字列は、使用されるUI要素に収まる必要があります。ドイツ語のコピーは英語より30〜40%長くなります。日本語は短くなる場合がありますが、異なる行高ルールが必要な場合があります。
アプリが実行中になるまで、誰も文字数を確認しません。TMSは生の文字列を表示し、レンダリングされたボタンは表示しません。「Start your free trial」と表示されるはずのドイツ語のコールトゥアクションは「Beginnen Sie Ihre kostenlose...」となり、ボタンの端で切れます。主要なCTAが主要市場の1つで表示されません。
67%のチームが本番環境でテキストのオーバーフローと切り捨てを経験しています。文字列ごとに文字数のバジェットを設定し、文字列レベルでチェックすることで、レンダリング前に長い文字列の問題を検出できます。
手動レビューが構造的エラーを見逃す理由
人間のレビュアーは意味を読みます。トーンの不一致、文化的なミス、ポルトガル語で不自然に聞こえるフレーズを検出します。文字列内で未解決のまま存在する{userName}は検出しません。なぜなら、無意識に入力済みの値として読んでしまうからです。
レビュアーもスケールで作業します。慎重なレビューの現実的なペースは1時間あたり20〜50文字列です。5言語にわたる50文字列のリリースは250の文字列レビューを意味します。構造的チェックは同じ250文字列に対してミリ秒で実行されます。
Common Sense Advisoryの2025年調査のデータは明確です。自動QAはすべての翻訳問題の70〜80%を検出し、厳格な用語集管理を持つチームでは90〜94%まで上昇します。残りの6〜30%は言語的および文化的であり、人間の判断が必要です。それが分業です。
コストの計算がこれを裏付けます。翻訳エラーが本番環境に達した後に修正するコストは、翻訳中に検出するコストの8〜12倍かかります(Nimdzi)。月2回のリリースで5言語を運用するチームにとって、この計算は急速に変わります。
3つの一般的な出発点があります。
手動プロセスの場合:バイリンガルのレビュアーが言語的な20%を検出します。構造的な80%は公開されます。レビュアーが気づかなかった変数は、2,000人のドイツ語ユーザーの前に表示されています。
エンタープライズTMSの場合:QAタブは存在しますが、プラットフォーム内で実行されます。デプロイ前にTMSから文字列がコピー&ペーストされると、QAタブはそれらを確認したことになりません。構造的エラーは裏口から出ていきます。
開発者専用CLIの場合:CIはファイルの構文を検証します。変数の保持、タグの整合性、用語集の一貫性は検証しません。これらのチェックには、形式だけでなく文字列コンテンツの認識が必要です。
体系的なローカリゼーションQAプロセスとはどのようなものか
体系的なプロセスは、5つの自動チェックを2つの時点で実行し、その上に人間のレビューを追加します。
テキストが更新されるたびに5つの評価者を継続的に実行してください。 チェックは自動的に2か所で実行されます。AI翻訳が生成されるとき、PrismyのAI翻訳エンジンは生成時にスペルチェック、変数保持、HTML整合性、用語集の一貫性、文字数チェックを実行します。構造的エラーは翻訳ファイルに入ることがありません。PrismyウェブアプリとChrome拡張機能で編集中は、エディターが変更をコミットする前にリアルタイムで問題がフラグされます。リリース後ではなく、リリース前に修正してください。
Prismyを初めて設定するときに、既存のテキストに対して評価者を一度実行してください。 ほとんどのチームは何年もかけて構築した翻訳ファイルを持っています。人間が書いた文字列、ツール間でコピー&ペーストされたもの、評価者の監視なしに編集されたもの。そのバックログには、静かに壊れた変数、不整合に適用された用語集用語、誰も確認していない画面でオーバーフローする文字数が含まれています。一度限りの監査パスで、本番公開前にすべてが表面化します。
Prismyの評価者は両方の時点を自動的に処理します。スペルチェック、変数チェック、HTML整合性、用語集マッチング、文字数バジェットはすべてのGitネイティブなプルリクエストとエディター内のインラインで実行されます。プロセスの上流を支えるAI翻訳品質については、完全ガイドをご覧ください。
-
スペルチェック自動化可能最もよく使用されるロケールから3つの翻訳キーを選び、スペルチェックツールで実行してください。レビュアーが読み流したタイポや文法のミスがすぐに表示されます。
-
変数保持自動化可能翻訳済みファイルで、ソースには存在するが翻訳には存在しない
{、%、{{を検索してください。見つかった場合、QAプロセスはそれを検出できていません。 -
HTMLタグ整合性自動化可能HTMLを含む翻訳済み文字列でタグバランスチェックを実行してください。本番環境で閉じられていない
<strong>や<a>があると、段落全体に太字またはリンクスタイルが適用されます。 -
用語集の一貫性自動化可能3つの主要な製品用語(主要CTA、製品名、機能名)を選んでください。それらがすべての言語のすべての文字列で同じように翻訳されているか確認してください。そうでない場合は、評価者に用語集チェックが必要です。
-
文字数とオーバーフロー自動化可能ドイツ語または他の長い拡張言語で製品を読み込んでください。すべてのボタンとラベルの切り捨てを確認してください。何かが切れている場合、文字数バジェットはQA時にチェックされていません。
FAQ
ローカリゼーションQAと翻訳レビューの違いは何ですか?
翻訳レビューとは、品質を確認する人間によるチェックです。トーン、正確さ、流暢さを確認します。ローカリゼーション品質保証にはそれに加えて自動化された機械的チェックが含まれます。スペルチェック、変数、HTML、用語集、文字数です。QAは人間のレビューの代わりではなく、その前に実行される必要があります。自動化レイヤーが構造的エラーを取り除くことで、人間のレビュアーは判断に集中できます。
リリース前にローカリゼーションをどのようにテストしますか?
4つのステップです。すべてのプルリクエストでの自動評価者(スペルチェック、変数、HTML、用語集、文字数)、実行中のアプリでのコンテキスト内人間レビュー、1言語での軽量リリーススモークテスト、そして製品用語に合わせて自動チェックを最新の状態に保つための四半期ごとの用語集監査です。堅実な翻訳QAプロセスには、文字列レベルのチェックでは見逃すオーバーフローやレンダリングの問題を検出するための実際のデバイス/画面コンテキストでのローカリゼーションテストも含まれます。
本番環境で翻訳品質管理の失敗を引き起こすものは何ですか?
通常は翻訳者ではありません。通常はプロセスです。翻訳者が評価者の監視なしにプレーンテキストで作業すると、変数の欠落が漏れます。用語集のドリフトは、何もチェックしないと用語を強制しません。文字数オーバーフローは、実際のUIでレンダリングされた文字列をテストしないと発生します。ほとんどの本番翻訳エラーは言語的ではなく構造的であり、ほとんどの構造的エラーは自動化可能です。
自動化ツールで人間の翻訳レビューを置き換えることはできますか?
構造的エラー(スペルチェック、変数、HTML、用語集、文字数)については:はい、そして人間よりも一貫性があり速く処理できます。言語的判断(トーン、文化的適合性、ニュアンス)については:いいえ。完全なローカリゼーションQAプロセスは両方を使用します。自動チェックが機械的な失敗を取り除き、人間のレビューが言語的な失敗を検出します。70〜94%の自動検出率は、人間のレビュアーが集中すべき6〜30%を残します。
業界の洞察をお見逃しなく!
ローカリゼーション、AI翻訳、製品の最新情報をメールでお届けします。
スパムなし、いつでも購読解除可能。プライバシーを尊重します。

シンプルで強力な方法でグローバル展開。
