2026年4月29日 · Industry
2026年のAIローカリゼーション: エンジン、レビュー、コラボレーション
AIローカリゼーションはモデルだけでは完結しません。本当のスタックには3つの層があります。エンジン、レビュー、コラボレーション。2026年のSaaSチーム向けワークフロー優先ガイドです。

PMが本番環境にあるフィーチャーのwordingを調整したいとします。JSONファイル内で適切なキーを探し、プレビューデプロイのために開発者の手を煩わせ、文言を練り直し、5言語で翻訳を再生成し、次のデプロイを待ちます。たった2語のために半日。エンジンは数秒で自分の仕事を終えています。その周囲のワークフローが本当の問題です。このガイドを読み終えると、AIローカリゼーションスタックの3層マップと、明日自分のsetupに対して実行できる15分間の監査が手に入ります。
2026年における「AIローカリゼーション」の本当の意味
AIローカリゼーションとは、大規模言語モデル(LLM)と品質評価ツールを使用して、リリースのスピードでプロダクトのテキストを翻訳、適応、レビューすることです。単なる翻訳以上の意味を持ちます。機能するAIローカリゼーションスタックは、用語集の管理、ブランドボイス、ハルシネーション検出、そして新しい文字列を本番環境に届けるまでの経路を処理します。
エンジンは真の閾値を超えました。2025年のメタ評価では、最先端のメトリクスが高リソース言語ペアにおいて人間の評価者の一致度に並ぶか上回ることが示されました(arxiv 2506.19571、2025年6月)。同論文では、COMMETが流暢なハルシネーションに高いスコアを与える点も指摘されています。エンジンはリリースに使えるほど優秀ですが、放置できるほどではありません。
市場データも同じ話をしています。言語サービス・テクノロジー業界は2023年に496億8,000万ドルの売上を記録しましたが、前年比4.5%減となり、生成AIが要因として挙げられています(CSA Research、2024年)。仕事は行われています。問題は誰がそれを指揮するかです。より長期的な視点については、本番環境におけるAI翻訳の品質に関する私たちの見解をご覧ください。
エンジンが解決済みなら、本当の課題はどこにあるのでしょうか。3つの層にあります。
3層スタック: エンジン、レビュー、コラボレーション
自作のPythonスクリプトからエンタープライズプラットフォームまで、あらゆるAIローカリゼーションツールは3つの層にマッピングできます。
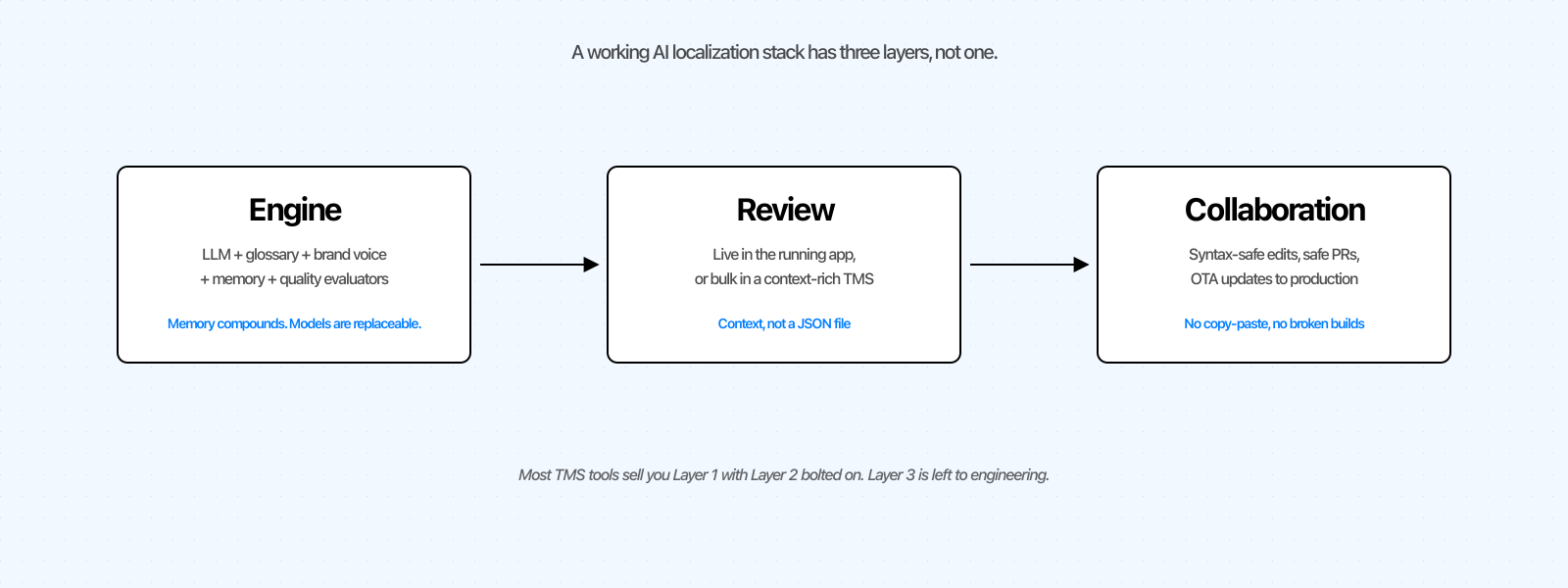
エンジン。 モデルに加え、用語集、ブランドボイス、カスタム指示、翻訳メモリ、品質評価ツール。大部分は標準化されていますが、一つのニュアンスがあります。メモリは蓄積されますが、モデルは蓄積されません。
レビュー。 人間がAIの出力を確認し、磨き上げる場所です。ほとんどのツールはAI以前に構築されており、翻訳者はフィーチャーリリース前にスプレッドシートから作業していました。現代のパターンはAIファースト: 自動翻訳してからコンテキスト内でレビューします。
コラボレーション。 テキストの変更がレビューから本番環境へと安全に移動する方法です。悪いコラボレーションとは、開発者が夜11時にJSONファイルに文字列を貼り付けることです。良いコラボレーションとは、構文エラーなしに、ループに入る必要のなかった人を煩わせることなく、変更が本番環境に届くことです。
スプレッドシートから始めた場合、自分でレイヤー1を作り、それ以外は何もない状態です。LokalisやCrowdinから来た場合、1つのプロダクトにレイヤー1と2がありますが、同期ドリブンのレイヤー3です。Lingo.devやLanguineから来た場合、強力なレイヤー1、レイヤー3用のCLI、そして非開発者向けのレイヤー2は実質的に存在しません。
適切なツールは、出発点によって異なります。各レイヤーを見ていきましょう。
レイヤー1: エンジン、ほぼ解決済み
モデルよりも受け取るコンテキストの方が重要です。用語集、ブランドボイスプロフィール、過去の翻訳を持つフロンティアLLMは、生の文字列を持つ同じモデルを毎回上回ります。用語集により「Submit」がすべてのページで同じように翻訳されます。ブランドボイスはフランス語とドイツ語で一貫したフォーマリティを保ちます。カスタム指示は、プロダクトの「Stage」がパイプラインのステップであり、劇場の舞台ではないことをモデルに伝えます。
翻訳メモリは、ほとんどのツールが過小評価している部分です。すべての手動編集はシグナルです。「ここではこう言う」というシグナルです。本格的なエンジンはそれらの編集を保存し、次の類似した文字列で表示し、モデルが同じ修正を繰り返さないようにパターンを特定します。メモリが長く稼働するほど、レビュアーの作業は少なくなります。モデルは交換可能ですが、メモリはそうではありません。
品質評価ツールは、エンジン単独では提供できないセーフティネットです。変数の保持、HTMLの整合性、用語集の不一致、文字数制限。これらは自動的に起動し、流暢に聞こえるがビルドを壊す失敗を検出します。Translated.comの分析では、COMMETが自信を持って訳しているが原文に忠実でない翻訳に過度に寛大なスコアを付けることが指摘されています(Translated.com、2025年)。COMMETだけに頼るベンダーは自分自身の反射を読んでいます。
規模感について: Smartlingは、Fortune 100の顧客が1年間で340万ドルを節約し、50%速くリリースした事例を公開しています(Smartling、2026年)。Prismyは用語集、ブランドボイス、翻訳メモリ、評価ツールをすぐに使える形で提供しています(AI翻訳エンジン)。
エンジンは標準化されています。本当の課題はレイヤー2にあります。
レイヤー2: レビュー、ライブでコンテキスト内で
私のレビュアーは、文字列をコンテキスト内で見る方法がなかったため、JSONファイルでAIの出力を書き直すのに3時間を費やしました。
レビューサーフェス。 非開発者がAIの出力を確認し、磨き上げる場所です。最良のものは実際に稼働しているアプリ自体です。
理想的なレビューはライブで行われます。自分のプロダクトを使い、おかしな表現を見つけ、その場で修正します。JSONファイルもなく、ダッシュボードもなく、開発者も不要です。ライブアプリ上のChromeオーバーレイが最もクリーンな表現です。すべての文字列がその場で編集可能で、周囲の画面がコンテキストになります。
ライブ編集はロングテールをカバーします。しかし、プロのプルーフリーダーがローンチ前に400の文字列を一括レビューするケースはカバーしません。その作業にはTMSが必要です。そこでのボトルネックはコンテキストの喪失です。UIのない文字列の行は適切に翻訳することが不可能です。
Prismyは、一括レビューのケース向けのTMSを、実際のUI内の各文字列のライブプレビューと、稼働中のアプリからポーリングされた自動スクリーンショットとペアリングしています。プルーフリーダーが必要とする一括フォーマットに、編集を良くするコンテキストを加えています。

Prismyが管理する文字列の平均レビュー時間は言語あたり15分で、レビュアーが生のJSONからコンテキストを再構築する場合の3時間以上と比較しています。この数字はタイピング速度に関するものではありません。各文字列がプロダクトのどこに位置するかを再構築しなくて済むことに関するものです。
レビューサーフェスが解決されると、3番目の問いが残ります。編集はどのように本番環境に届くのでしょうか。
レイヤー3: コラボレーション、変更を安全に本番環境へ届ける
レビュアーがスプレッドシートで20個の変更を行い、今それをJSONファイルに貼り付けています。閉じ括弧を忘れてしまい、stagingのビルドが赤くなっています。
コラボレーション。 「レビュアーが文言を変更した」から「変更が本番環境でライブになった」までの経路を、開発者が監視しなくてもよいようにすることです。
スプレッドシートのワークフローを想像してください。レビュアーが共有シートで20の文字列を編集します。開発者またはPMがそれをコードベースにコピー&ペーストします。1行に余分なカンマが入ります。別の行で{userName}変数が失われます。ビルドが壊れます。すべてのリリース、すべての言語、すべてのレビュアーに掛け算です。
良いコラボレーションはそのループを排除します。レビュアーの編集は、開発者がワンクリックでマージする小さなpull requestとして届きます。3つのことがそれを可能にします。
- 構文の安全性。 自動的に検証されます。変数の保持、HTMLタグのクローズ、用語集の遵守、文字数制限の順守。アプリを壊すような変更はPRに届きません。
- Pull requestでの引き渡し。 PRは開発者に何が変わったかを正確に示します。コードに使う同じdiffビューです。GitHubローカリゼーションワークフローとGitLab連携をご覧ください。
- Over-the-airアップデート。 モバイルとCDN配信のプロダクトでは、OTAにより金曜日の夕方5時のテキスト修正が週末前に本番環境に反映されます。アプリのリリースは不要です。
シリーズAのIoT顧客は、翻訳ファイルのGitHubコンフリクトが週次の火種からゼロになり、月に3〜4日節約できたと報告しています。Crowdinは、75%のAI生成翻訳が編集なしで承認され、約8万ドルを節約したPolhusのケーススタディを公開しました(Crowdin、2026年)。
開発者が火曜日の午後に文字列を貼り付けることに時間を費やすべきではありません。では、ビルドか購入かの意思決定です。
ビルドか購入か: AIローカリゼーションの意思決定フレームワーク
購入 する場合: 2つ以上の言語でリリースしており、10人以上のプロダクトエンジニアがいて、ローカリゼーションが設定のダンプ以上のものである場合。レビューサーフェスの欠如のコストは、追加する言語とペルソナごとに複利で増えていきます。
構築 する場合: セキュリティモデルがサードパーティのアクセスを禁じている場合(稀で、多くはホスティングモードオプションで対応可能)、または規制された使用ケースがある場合。そうでなければ、3つすべての層を構築するコストは、エンジニア1人の6〜12ヶ月の作業と継続的なメンテナンスです。
悪い購入のコストは、購入しないコストよりも一般的です。誰も使わないエンタープライズTMS。PMが触れないCLI。5番目の言語で壊れるスプレッドシートワークフロー。この決断は「最高のAI翻訳ツール」ではありません。「どのワークフローが自分のチームに合うか」です。
このポストが主張する意見: AI翻訳品質は解決済みです。本当のプロダクトはワークフローです。レビューサーフェスとコラボレーションフローがチームがすでに働く方法に合っているツールを選んでください。最も長い機能リストを持つものではありません。エンジン品質だけでツールを評価しているなら、昨日の問いに答えています。
AIローカリゼーション15分間監査
自分のsetupに対してこれを実行してください。それぞれの「いいえ」は、開発者が本来別の人がやるべきローカリゼーション作業を引き受けている場所、またはテキストが準備できていないためにリリースが止まる場所です。
7つの質問による監査
ほとんど「いいえ」= スタックがエンジニアリング時間を消費していますプロダクトエンジニアリングおよびローカリゼーションリード向けのクイック自己評価。
- エンジンPMがチケットを出さずに編集できる用語集がありますか?
- エンジンマージ前に壊れた変数、欠落したHTML、用語集の不一致をフラグするツールがありますか?
- レビューUXライターがFigma内でデザインのコンテキストに合わせて文言をレビューできますか?
- レビューネイティブスピーカーのレビュアーがJSONファイルに触れずにライブアプリで文字列を磨けますか?
- コラボレーションツールが手動コピー&ペーストのステップなしに新しい文字列のクリーンなGit PRを開きますか?
- コラボレーション金曜日の夕方5時にフランス語の文字列が間違っていた場合、非開発者が開発者を煩わせずに本番環境で修正できますか?
- スケーリングチームがヘッドカウントを増やさずに6番目の言語を追加できますか?
ほとんど「いいえ」? Prismyはまさにこのために構築されました。GitHubまたはGitLabを接続して、当日中に最初のAI翻訳PRをリリースしましょう。
Prismyを試す →スケーリングの問いは理論的なものではありません。Alexis、Figures: 「2言語からほぼ10言語へ、美しい一貫性で。」そのチームは2言語のアドホックなsetupから9言語の本番スタックへ、ローカリゼーションの役割を追加せずに移行しました。スタックがそこまで連れて行けない場合、ワークフローの問題を抱えています。エンジンの問題ではありません。
よくある質問
AIローカリゼーションとは何ですか?
AIローカリゼーションとは、LLMと品質評価ツールを使用してリリースのスピードでプロダクトのテキストを翻訳、適応、レビューすることです。用語集の管理、ブランドボイス、翻訳メモリ、ハルシネーション検出、本番環境への安全な引き渡しをカバーします。
AIローカリゼーションと機械翻訳はどう違いますか?
機械翻訳はエンジン単独です。ソースが入り、ターゲットが出ます。AIローカリゼーションはエンジンにワークフローを加えたものです。用語集、ブランドボイス、翻訳メモリ、レビューサーフェス、GitネイティブまたはOTAのコラボレーション経路です。
AI翻訳は本番環境に使えるほど優秀ですか?
高リソース言語とプロダクトコピーについては、品質評価ツールと人間のレビューを重ねることで、はい。法的、医療的、またはクリエイティブなコンテンツについては、まだです。2025年の文献は、一般的な言語ペアでのエンジンの同等性とハルシネーションの盲点を示しています。
AIは人間の翻訳者を置き換えられますか?
いいえ。AIは初稿のボリュームを処理します。人間はニュアンス、ブランドボイスのレビュー、ハイリスクなコンテンツを処理します。経済性は翻訳からレビューへとシフトします。
AIローカリゼーションのコストはいくらですか?
エンジンのコストはフロンティアLLMで文字列あたり約1〜3セントです。TMSと比較してほとんどの節約はレビューとコラボレーションから生まれます。モデルからではありません。総支出の50%削減が一般的な規模感です。
2026年の最高のAIローカリゼーションプラットフォームは何ですか?
一つの答えはありません。マネージドサービスの予算があればエンジンファースト。Gitからリリースし、PM、UXライター、レビュアーをループに入れる必要があればワークフローファースト。
業界の洞察をお見逃しなく!
ローカリゼーション、AI翻訳、製品の最新情報をメールでお届けします。
スパムなし、いつでも購読解除可能。プライバシーを尊重します。

シンプルで強力な方法でグローバル展開。
