29 aprile 2026 · Industry
Localizzazione con IA nel 2026: motore, revisione e collaborazione
La localizzazione con IA va oltre il modello. Il vero stack ha tre livelli: motore, revisione e collaborazione. Una guida orientata al workflow per i team SaaS nel 2026.

Un PM vuole affinare il wording di una funzionalità in produzione. Cerca in un file JSON le chiavi giuste, disturba uno sviluppatore per pubblicare un deployment di preview, itera sulla formulazione, riavvia la traduzione in cinque lingue e aspetta un altro deployment. Mezza giornata per due parole. Il motore ha fatto la sua parte in pochi secondi. Il workflow intorno ad esso è il vero problema. Alla fine di questa guida, avrete una mappa a tre livelli di uno stack di localizzazione con IA e un audit di 15 minuti da eseguire sul proprio setup domani.
Cosa significa davvero «localizzazione con IA» nel 2026
La localizzazione con IA è l'uso di modelli linguistici di grandi dimensioni e valutatori di qualità per tradurre, adattare e revisionare i testi dei prodotti alla velocità dei rilasci. Va oltre la traduzione. Uno stack di localizzazione con IA funzionante gestisce il controllo del glossario, la voce del brand, il rilevamento delle allucinazioni e il percorso che porta le nuove stringhe in produzione.
Il motore ha superato una soglia reale. Una meta-valutazione del 2025 ha rilevato che le metriche allo stato dell'arte raggiungono o superano ora i livelli di concordanza tra valutatori umani per le coppie di lingue ad alta disponibilità (arxiv 2506.19571, giugno 2025). Lo stesso articolo sottolinea che COMET assegna punteggi generosi alle allucinazioni fluenti, quindi il motore è abbastanza buono per essere usato in produzione, ma non abbastanza buono per essere lasciato senza supervisione.
I dati di mercato raccontano la stessa storia. Il settore dei servizi linguistici e della tecnologia ha generato 49,68 miliardi di dollari nel 2023, in calo del 4,5 per cento anno su anno, con l'IA generativa citata come fattore contribuente (CSA Research, 2024). Il lavoro viene svolto. La domanda è chi lo orchestra. Per una prospettiva più ampia, consultate la nostra analisi sulla qualità della traduzione con IA in produzione.
Se il motore è risolto, dove si trova il vero problema? In tre livelli.
Lo stack a tre livelli: motore, revisione e collaborazione
Ogni strumento di localizzazione con IA, dallo script Python artigianale alla piattaforma enterprise, può essere mappato su tre livelli.
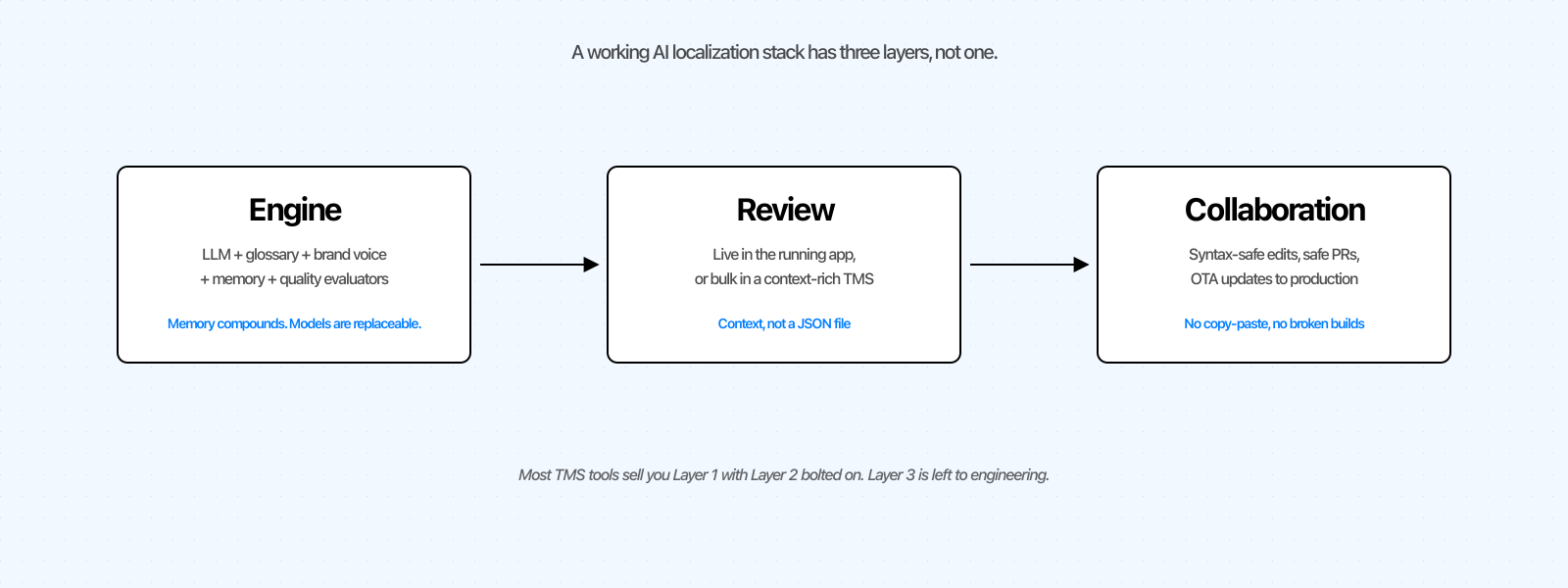
Motore. Il modello, più il glossario, la voce del brand, le istruzioni personalizzate, la memoria di traduzione e i valutatori di qualità. In gran parte standardizzato, con una sfumatura: la memoria si accumula, i modelli no.
Revisione. Dove un essere umano controlla e perfeziona l'output dell'IA. La maggior parte degli strumenti è stata sviluppata prima dell'IA, quando i traduttori lavoravano da fogli di calcolo prima che la funzionalità venisse rilasciata. Il moderno pattern è IA-prima: traduzione automatica, poi revisione nel contesto.
Collaborazione. Come una modifica ai testi passa dalla revisione alla produzione in modo sicuro. La cattiva collaborazione è uno sviluppatore che incolla stringhe in un file JSON alle 23. La buona collaborazione significa che la modifica raggiunge la produzione senza errori di sintassi e senza disturbare chi non aveva bisogno di essere coinvolto.
Se siete partiti da un foglio di calcolo, avete il livello 1 fatto da soli e nient'altro. Se siete venuti da Lokalise o Crowdin, avete i livelli 1 e 2 in un unico prodotto, ma un livello 3 basato sulla sincronizzazione. Se siete venuti da Lingo.dev o Languine, avete un livello 1 solido, una CLI per il livello 3 e nessun vero livello 2 per i non sviluppatori.
Lo strumento giusto dipende dal punto di partenza. Analizziamo ogni livello.
Livello 1: il motore, in gran parte risolto
Il modello conta meno del contesto che riceve. Un LLM frontier con un glossario, un profilo di voce del brand e traduzioni precedenti supera ogni volta lo stesso modello con stringhe grezze. Il glossario garantisce che «Submit» venga reso nello stesso modo su ogni pagina. La voce del brand mantiene la formalità coerente tra il francese e il tedesco. Le istruzioni personalizzate indicano al modello che «Stage» nel vostro prodotto è una fase di pipeline, non una scena teatrale.
La memoria di traduzione è la parte che la maggior parte degli strumenti sottovaluta. Ogni modifica manuale è un segnale: è così che lo diciamo qui. Un motore serio memorizza quelle modifiche, le mostra alla successiva stringa simile e identifica i pattern in modo che il modello smetta di ripetere le stesse correzioni. Più a lungo funziona la memoria, meno lavoro ha il revisore. Il modello è sostituibile. La memoria no.
I valutatori di qualità sono la rete di sicurezza che il motore da solo non può fornire. Preservazione delle variabili, integrità dell'HTML, discrepanze nel glossario, budget di lunghezza. Si attivano automaticamente e catturano i fallimenti che suonano fluenti ma rompono il build. L'analisi di Translated.com sottolinea che COMET assegna valori eccessivamente generosi alle traduzioni che suonano bene ma sono infedeli all'originale (Translated.com, 2025). I fornitori che si affidano solo a COMET stanno leggendo il proprio riflesso.
Ordine di grandezza: Smartling ha pubblicato un caso di un cliente Fortune 100 che ha risparmiato 3,4 milioni di dollari in un anno e rilasciato il 50 per cento più velocemente (Smartling, 2026). Prismy include glossario, voce del brand, memoria di traduzione e valutatori pronti all'uso (motore di traduzione con IA).
I motori sono standardizzati. Il vero dolore si trova nel livello 2.
Livello 2: revisione, dal vivo e nel contesto
Il mio revisore ha trascorso tre ore a riscrivere l'output dell'IA in un file JSON perché non c'era modo di vedere le stringhe nel contesto.
Superficie di revisione. Dove un non sviluppatore controlla e perfeziona l'output dell'IA. La migliore è l'app stessa in esecuzione.
La revisione ideale avviene dal vivo. Si usa il proprio prodotto, si individua una frase che suona strana e la si corregge sul momento. Nessun file JSON, nessun dashboard, nessuno sviluppatore in mezzo. Un overlay Chrome sull'app live è l'espressione più chiara: ogni stringa modificabile al suo posto, con lo schermo circostante come contesto.
Le modifiche dal vivo coprono la coda lunga. Non coprono il caso in cui un correttore di bozze professionale revisiona quattrocento stringhe prima del lancio. Quel lavoro ha bisogno di un TMS. Il collo di bottiglia lì è la perdita di contesto: una riga di stringhe senza interfaccia utente intorno è impossibile da tradurre bene.
Prismy abbina un TMS per il caso massiccio con anteprime live di ogni stringa nell'interfaccia utente reale e screenshot automatici prelevati dall'app in esecuzione. Il formato massivo di cui ha bisogno il correttore, con il contesto che rende buona la modifica.

Il tempo medio di revisione di una stringa gestita da Prismy è di 15 minuti per lingua, rispetto a tre o più ore quando il revisore ricostruisce il contesto dal JSON grezzo. Il numero non riguarda la velocità di digitazione. Riguarda il non dover ricostruire dove si trova ogni stringa nel prodotto prima di formularla.
Se la superficie di revisione è risolta, rimane la terza domanda: come arriva la modifica in produzione?
Livello 3: collaborazione, portare la modifica in produzione in modo sicuro
Il revisore ha fatto venti modifiche nel foglio di calcolo e ora le sto incollando nel file JSON. Ho dimenticato una parentesi graffa di chiusura e il build di staging è rosso.
Collaborazione. Il percorso da «il revisore ha cambiato i testi» a «la modifica è live in produzione», senza che uno sviluppatore debba sorvegliarla.
Immaginate il workflow del foglio di calcolo. Il revisore modifica venti stringhe in un foglio condiviso. Uno sviluppatore o PM le copia e incolla nel codebase. Una riga riceve una virgola in più. Un'altra perde una variabile {userName}. Il build si rompe. Moltiplicato per ogni rilascio, ogni lingua, ogni revisore.
La buona collaborazione elimina quel ciclo. La modifica del revisore arriva come una piccola pull request che lo sviluppatore unisce con un clic. Tre cose lo rendono possibile:
- Sicurezza sintattica. Validata automaticamente: variabili preservate, tag HTML chiusi, glossario rispettato, budget di lunghezza rispettati. Una modifica che romperebbe l'app non arriva mai alla PR.
- Consegna tramite pull request. La PR mostra allo sviluppatore esattamente cosa è cambiato, nella stessa vista diff che usa per il codice. Consultate il workflow di localizzazione con GitHub e l'integrazione con GitLab.
- Aggiornamenti over-the-air. Per i prodotti mobile e serviti via CDN, OTA significa che una correzione ai testi alle 17 del venerdì arriva in produzione prima del weekend senza un rilascio dell'app.
Un cliente IoT in Serie A ha riferito che i conflitti di GitHub sui file di traduzione sono passati da un problema settimanale a zero, risparmiando da tre a quattro giorni al mese. Crowdin ha pubblicato un caso di studio di Polhus con il 75 per cento di traduzioni generate dall'IA approvate senza modifiche e un risparmio di circa 80.000 dollari (Crowdin, 2026).
Uno sviluppatore non dovrebbe mai passare un martedì pomeriggio a incollare stringhe. Ora, la decisione di costruire o comprare.
Costruire o comprare: un framework decisionale per la localizzazione con IA
Comprate se lanciate in due o più lingue, avete dieci o più ingegneri di prodotto e la vostra localizzazione è più di un semplice dump di configurazione. Il costo di una superficie di revisione assente si accumula con ogni lingua e persona che aggiungete.
Costruite se il vostro modello di sicurezza vieta l'accesso di terze parti (raro, spesso risolto da un'opzione hosted mode) o avete un caso d'uso regolamentato. Altrimenti il costo di costruire tutti e tre i livelli è di sei-dodici mesi di attenzione di un ingegnere, più la manutenzione continua.
Il costo di comprare male è più comune del costo di comprare. Un TMS enterprise che nessuno usa. Una CLI che il PM non può toccare. Un workflow su fogli di calcolo che si rompe alla quinta lingua. La decisione non è «miglior strumento di traduzione con IA». È «quale workflow si adatta al mio team».
L'opinione che questo articolo sostiene: la qualità della traduzione con IA è risolta. Il vero prodotto è il workflow. Scegliete lo strumento la cui superficie di revisione e il cui flusso di collaborazione corrispondono al modo in cui il vostro team già lavora, non quello con la lista di funzionalità più lunga. Se state ancora valutando gli strumenti solo per la qualità del motore, state rispondendo alla domanda di ieri.
Un audit di localizzazione con IA di 15 minuti
Eseguite questo sul vostro setup. Ogni «no» è un punto in cui il vostro sviluppatore finisce per fare lavoro di localizzazione che dovrebbe fare qualcun altro, o dove un rilascio si blocca perché i testi non sono pronti.
L'audit in 7 domande
Perlopiù «no» = il vostro stack vi sta costando ore di sviluppoAutovalutazione rapida per i responsabili di product engineering e localizzazione.
- MotoreAvete un glossario che il PM può modificare senza aprire un ticket?
- MotoreIl vostro strumento segnala variabili rotte, HTML mancante o discrepanze nel glossario prima del merge?
- RevisioneIl vostro UX writer può revisionare i testi dentro Figma, nel contesto del design?
- RevisioneUn revisore madrelingua può perfezionare una stringa nell'app live, senza toccare un file JSON?
- CollaborazioneIl vostro strumento apre una PR Git pulita per le nuove stringhe, senza nessun passaggio manuale di copia?
- CollaborazioneQuando una stringa in francese è sbagliata il venerdì alle 17, un non sviluppatore può correggerla in produzione senza disturbare lo sviluppatore?
- ScalabilitàIl vostro team può aggiungere una sesta lingua senza assumere nuovo personale?
Perlopiù «no»? Prismy è stato sviluppato esattamente per questo. Collegate GitHub o GitLab e rilasciate la vostra prima PR di traduzione con IA lo stesso giorno.
Scoprite Prismy →La domanda sulla scalabilità non è teorica. Alexis, Figures: «Da due lingue a quasi dieci con una coerenza impeccabile.» Quel team è passato da un setup ad hoc a due lingue a uno stack di produzione a nove lingue senza aggiungere un ruolo di localizzazione. Se il vostro stack non riesce a portarvi lì, avete un problema di workflow, non un problema di motore.
FAQ
Cos'è la localizzazione con IA?
La localizzazione con IA è l'uso di LLM e valutatori di qualità per tradurre, adattare e revisionare i testi dei prodotti alla velocità dei rilasci. Comprende il controllo del glossario, la voce del brand, la memoria di traduzione, il rilevamento delle allucinazioni e la consegna sicura in produzione.
In cosa si differenzia la localizzazione con IA dalla traduzione automatica?
La traduzione automatica è il motore da solo: testo di origine in entrata, testo di destinazione in uscita. La localizzazione con IA è il motore più il workflow: glossario, voce del brand, memoria di traduzione, superfici di revisione e un percorso di collaborazione nativo Git o OTA.
La traduzione con IA è abbastanza buona per la produzione?
Per le lingue ad alta disponibilità e i testi di prodotto, sì, con valutatori di qualità e revisione umana. Per i contenuti legali, medici o creativi, non ancora. La letteratura del 2025 mostra la parità del motore sulle coppie più comuni insieme a punti ciechi nelle allucinazioni.
L'IA può sostituire i traduttori umani?
No. L'IA gestisce il volume della prima bozza. Gli esseri umani gestiscono le sfumature, la revisione della voce del brand e i contenuti ad alto rischio. L'economia si sposta dalla traduzione alla revisione.
Quanto costa la localizzazione con IA?
Il costo del motore è di circa uno-tre centesimi per stringa con un LLM frontier. La maggior parte dei risparmi rispetto a un TMS si trova nella revisione e nella collaborazione, non nel modello. Una riduzione del 50 per cento della spesa totale è un ordine di grandezza comune.
Qual è la migliore piattaforma di localizzazione con IA nel 2026?
Nessuna risposta unica. Motore-prima se avete un budget per i servizi gestiti. Workflow-prima se rilasciate da Git e avete bisogno di PM, UX writer e revisori nel ciclo.
Non perda le nostre analisi di settore!
Riceva le ultime novità su localizzazione, traduzioni con IA e aggiornamenti di prodotto direttamente nella Sua casella di posta.
Niente spam, annulli l'iscrizione in qualsiasi momento. Rispettiamo la Sua privacy.

Vai globale, in modo semplice e potente.
