April 29, 2026 · Industry
AI Localization in 2026: Engine, Review, Collaboration
AI localization is more than the model. The real stack has three layers: engine, review, collaboration. A workflow-first guide for SaaS teams in 2026.

A PM wants to tweak the wording of a feature in production. They grep the repo for the right keys, ping a dev to spin up a preview deploy, iterate on the phrasing, retrigger translation in five languages, then wait for another deploy. Half a day for two words. The engine did its part in seconds. The workflow around it is the actual problem. By the end of this guide you will have a three-layer map of an AI localization stack and a 15-minute audit you can run on your own setup tomorrow.
What "AI localization" actually means in 2026
AI localization is the use of large language models and quality evaluators to translate, adapt, and review product copy at the speed of release. It is more than translation. A working AI localization stack handles glossary control, brand voice, hallucination catching, and the path that gets the new strings into production.
The engine has crossed a real threshold. A 2025 meta-evaluation found that state-of-the-art metrics now match or surpass human-rater agreement levels for high-resource pairs (arxiv 2506.19571, June 2025). The same paper notes that COMET assigns generous scores to fluent hallucinations, so the engine is good enough to ship and not good enough to leave alone.
Market data tells the same story. The language services and technology industry generated $49.68B in 2023, down 4.5 percent year-over-year, with generative AI cited as a contributor (CSA Research, 2024). The work is being done. The question is who orchestrates it. For a longer view, see our take on AI translation quality in production.
If the engine is solved, where does the actual pain live? In three layers.
The three-layer stack: engine, review, collaboration
Every AI localization tool, from the homegrown Python script to the enterprise platform, can be mapped onto three layers.
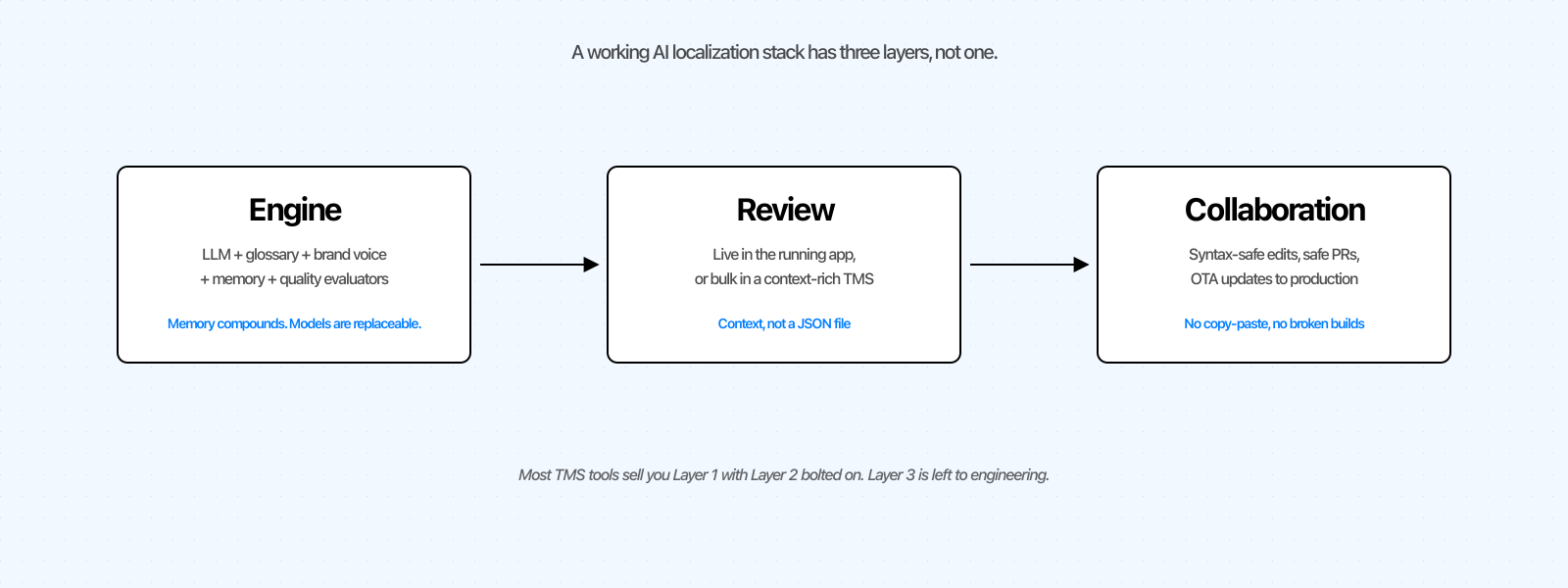
Engine. The model, plus glossary, brand voice, custom instructions, translation memory, and quality evaluators. Mostly commoditized, with one nuance: memory compounds, models do not.
Review. Where a human checks and polishes the AI output. Most tools were built before AI, when translators worked from spreadsheets before the feature shipped. The modern pattern is AI-first: auto-translate, then review in context.
Collaboration. How a wording change moves from review to production safely. Bad collaboration is an engineer copy-pasting strings into a JSON file at 11 PM. Good collaboration is the change reaching production without syntax breakage and without disturbing anyone who did not need to be in the loop.
If you came from a spreadsheet, you have layer 1 do-it-yourself and nothing else. If you came from Lokalise or Crowdin, you have layers 1 and 2 in one product but a sync-driven layer 3. If you came from Lingo.dev or Languine, you have a strong layer 1, a CLI for layer 3, and no real layer 2 for non-developers.
The right tool depends on which starting point you are at. Let us walk each layer.
Layer 1: the engine, mostly solved
The model matters less than the context it gets. A frontier LLM with a glossary, brand voice profile, and prior translations beats the same model with raw strings every time. The glossary keeps "Submit" rendered the same way across every page. The brand voice keeps formality consistent across French and German. Custom instructions tell the model that "Stage" in your product is a pipeline step, not a theater scene.
Translation memory is the part most tools underestimate. Every manual edit is a signal: this is how we say it here. A serious engine stores those edits, surfaces them on the next similar string, and identifies patterns so the model stops repeating the same fixes. The longer the memory runs, the less work the reviewer has to do. The model is replaceable. The memory is not.
Quality evaluators are the safety net the engine cannot provide alone. Variable preservation, HTML integrity, glossary mismatches, length budgets. These fire automatically and catch failures that read fluent but break the build. The Translated.com analysis notes that COMET assigns overly generous values to confident-but-unfaithful translations (Translated.com, 2025). Vendors leaning only on COMET are reading their own reflection.
For order of magnitude: Smartling published a Fortune 100 customer saving $3.4M in a year and shipping 50 percent faster (Smartling, 2026). Prismy ships glossary, brand-voice, memory, and evaluators out of the box (AI translation engine).
Engines are commoditized. The actual pain lives in Layer 2.
Layer 2: review, live and in context
My reviewer spent three hours rewriting AI output in a JSON file because there was no way to see the strings in context.
Review surface. Where a non-developer checks and polishes the AI output. The best one is the running app itself.
The ideal review happens live. You are using your own product, you spot a phrase that reads off, you fix it on the spot. No JSON file, no dashboard, no developer in the loop. A Chrome overlay on the live app is the cleanest expression: every string editable in place, with the surrounding screen as context.
Live edits cover the long tail. They do not cover the case where a professional proofreader bulk-reviews four hundred strings before launch. That work needs a TMS. The bottleneck there is loss of context: a row of strings with no UI around them is impossible to translate well.
Prismy pairs a TMS for the bulk case with live previews of each string in the actual UI, and auto-screenshots polled from the running app. The bulk format the proofreader needs, with the context that makes the edit good.

Average review time on a Prismy-managed string is 15 minutes per language, against three or more hours when the reviewer rebuilds context from raw JSON. The number is not about typing speed. It is about not having to reconstruct where each string sits in the product before phrasing it.
If the review surface is solved, the third question remains: how does the edit reach production?
Layer 3: collaboration, getting the change to production safely
The reviewer made twenty changes in the spreadsheet and now I am pasting them into the JSON file. I missed a closing brace and the staging build is red.
Collaboration. The path from "the reviewer changed the wording" to "the change is live in production", without a developer having to babysit it.
Picture the spreadsheet workflow. The reviewer edits twenty strings in a shared sheet. A developer or PM copy-pastes them into the codebase. One row gets a stray comma. Another loses a {userName} variable. The build breaks. Multiply by every release, every language, every reviewer.
Good collaboration removes that loop. The reviewer's edit lands as a small pull request the developer merges in one click. Three things make it possible:
- Syntax safety. Validated automatically: variables preserved, HTML tags closed, glossary respected, length budgets honored. A change that would break the app never reaches the PR.
- Pull-request handoff. The PR shows the developer exactly what changed, in the same diff view they use for code. See the GitHub localization workflow and the GitLab integration.
- Over-the-air updates. For mobile and CDN-served products, OTA means a wording fix at 5 PM on Friday lands in production before the weekend without an app release.
A Series A IoT customer reported GitHub conflicts on translation files going from a weekly fire to none, saving three to four days a month. Crowdin published a Polhus case study with 75 percent AI-generated translations approved without edits and roughly $80,000 saved (Crowdin, 2026).
A developer should never spend a Tuesday afternoon copy-pasting strings. Now the build-versus-buy decision.
Build versus buy: a decision framework for AI localization
Buy if you ship in two or more languages, you have ten or more product engineers, and your localization is more than a config dump. The cost of a missing review surface compounds with every language and persona you add.
Build if your security model forbids third-party access (rare, often addressed by a hosted-mode option) or you have a regulated use case. Otherwise the cost of building all three layers is six to twelve months of one engineer's attention, plus ongoing maintenance.
The cost of buying badly is more common than the cost of buying. An enterprise TMS that nobody uses. A CLI that the PM cannot touch. A spreadsheet workflow that breaks at language five. The decision is not "best AI translation tool". It is "which workflow matches my team."
The opinion this post argues toward: AI translation quality is solved. The actual product is the workflow. Pick the tool whose review surface and collaboration flow match how your team already works, not the one with the longest feature list. If you are still scoring tools by engine quality alone, you are answering yesterday's question.
A 15-minute AI localization audit
Run this on your own setup. Each "no" is a place where your developer ends up doing localization work that someone else should be doing, or where a release stalls because the wording is not ready.
The 7-question audit
Mostly no = your stack is costing you engineering hoursQuick self-assessment for product engineering and localization leads.
- EngineDo you have a glossary the PM can edit without filing a ticket?
- EngineDoes your tool flag broken variables, missing HTML, or glossary mismatches before merge?
- ReviewCan your UX writer review wording inside Figma, in context with the design?
- ReviewCan a native-speaker reviewer polish a string in the live app, without touching a JSON file?
- CollaborationDoes your tool open a clean Git PR for new strings, with no manual copy-paste step?
- CollaborationWhen a French string is wrong on Friday at 5 PM, can a non-developer fix it in production without disturbing the developer?
- ScalingCan your team add a sixth language without adding a headcount?
Mostly "no"? Prismy was built to fix exactly this. Connect GitHub or GitLab and ship your first AI translation PR the same day.
Discover Prismy →The scaling question is not theoretical. Alexis, Figures: "From two languages to almost ten with beautiful consistency." That team went from a two-language ad-hoc setup to a nine-language production stack without adding a localization role. If your stack cannot get you there, you have a workflow problem, not an engine problem.
FAQ
What is AI localization?
AI localization is the use of LLMs and quality evaluators to translate, adapt, and review product copy at the speed of release. It covers glossary control, brand voice, memory, hallucination catching, and safe handoff to production.
How is AI localization different from machine translation?
Machine translation is the engine in isolation: source in, target out. AI localization is the engine plus the workflow: glossary, brand voice, memory, review surfaces, and a Git-native or OTA collaboration path.
Is AI translation good enough for production?
For high-resource languages and product copy, yes, with quality evaluators and human review on top. For legal, medical, or creative content, not yet. The 2025 literature shows engine parity on common pairs alongside hallucination blind spots.
Can AI replace human translators?
No. AI handles first-pass volume. Humans handle nuance, brand voice review, and high-stakes content. The economics shift from translation to review.
How much does AI localization cost?
Engine cost is roughly one to three cents per string with a frontier LLM. Most savings versus a TMS show up in review and collaboration, not in the model. A 50 percent reduction in total spend is a common order of magnitude.
What is the best AI localization platform in 2026?
No single answer. Engine-first if you have a managed-services budget. Workflow-first if you ship from Git and need PMs, UX writers, and reviewers in the loop.
Don't miss our industry insights!
Get the latest insights on localization, AI translations, and product updates delivered to your inbox.
No spam, unsubscribe at any time. We respect your privacy.

Go global, the simple and powerful way.
