29 de abril de 2026 · Industry
Localização com IA em 2026: motor, revisão e colaboração
A localização com IA vai além do modelo. O stack real tem três camadas: motor, revisão e colaboração. Um guia orientado ao workflow para equipas SaaS em 2026.

Um PM quer afinar o wording de uma funcionalidade em produção. Procura num ficheiro JSON as chaves certas, incomoda um dev para lançar um deployment de preview, itera na formulação, relança a tradução em cinco línguas e espera por outro deployment. Meio dia por duas palavras. O motor fez a sua parte em segundos. O workflow à sua volta é o verdadeiro problema. No final deste guia, terão um mapa de três camadas de um stack de localização com IA e uma auditoria de 15 minutos para aplicar ao vosso próprio setup amanhã.
O que significa realmente «localização com IA» em 2026
A localização com IA é o uso de grandes modelos de linguagem e avaliadores de qualidade para traduzir, adaptar e rever textos de produtos à velocidade dos lançamentos. É mais do que tradução. Um stack de localização com IA funcional gere o controlo do glossário, o tom de voz, a deteção de alucinações e o caminho que leva as novas cadeias de texto para produção.
O motor cruzou um limiar real. Uma meta-avaliação de 2025 revelou que as métricas de ponta igualam ou superam agora os níveis de concordância entre avaliadores humanos para pares de línguas de alta disponibilidade (arxiv 2506.19571, junho de 2025). O mesmo artigo assinala que o COMET atribui pontuações generosas a alucinações fluentes, pelo que o motor é suficientemente bom para usar em produção, mas não suficientemente bom para ser deixado sem supervisão.
Os dados de mercado contam a mesma história. O sector de serviços linguísticos e tecnologia gerou 49,68 mil milhões de dólares em 2023, uma queda de 4,5 por cento face ao ano anterior, com a IA generativa citada como fator (CSA Research, 2024). O trabalho está a ser feito. A questão é quem o orquestra. Para uma perspetiva mais alargada, consulte a nossa análise sobre qualidade da tradução com IA em produção.
Se o motor está resolvido, onde está a dor real? Em três camadas.
O stack de três camadas: motor, revisão e colaboração
Todas as ferramentas de localização com IA, desde o script Python artesanal até à plataforma enterprise, podem ser mapeadas em três camadas.
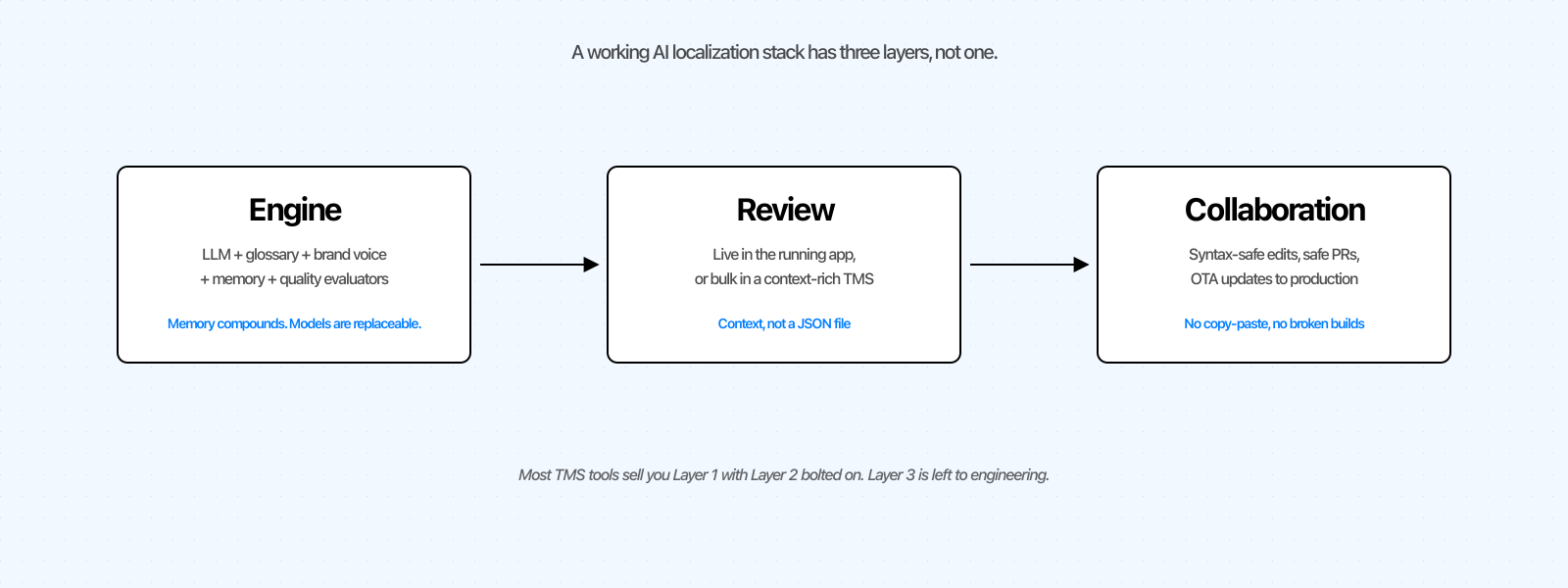
Motor. O modelo, mais o glossário, o tom de voz, as instruções personalizadas, a memória de tradução e os avaliadores de qualidade. Em grande parte estandardizado, com um matiz: a memória acumula-se, os modelos não.
Revisão. Onde um ser humano verifica e aperfeiçoa a saída da IA. A maioria das ferramentas foi construída antes da IA, quando os tradutores trabalhavam a partir de folhas de cálculo antes de a funcionalidade ser lançada. O padrão moderno é IA-primeiro: tradução automática e depois revisão em contexto.
Colaboração. Como uma alteração de texto passa da revisão para produção de forma segura. A má colaboração é um programador a colar cadeias de texto num ficheiro JSON às 23h. A boa colaboração significa que a alteração chega a produção sem erros de sintaxe e sem perturbar quem não precisava de estar no processo.
Se a equipa partiu de uma folha de cálculo, tem a camada 1 feita por conta própria e nada mais. Se veio do Lokalise ou do Crowdin, tem as camadas 1 e 2 num único produto, mas uma camada 3 baseada em sincronização. Se veio do Lingo.dev ou do Languine, tem uma camada 1 sólida, uma CLI para a camada 3 e nenhuma camada 2 real para não programadores.
A ferramenta certa depende do ponto de partida. Vamos analisar cada camada.
Camada 1: o motor, em grande parte resolvido
O modelo importa menos do que o contexto que recebe. Um LLM de fronteira com um glossário, um perfil de tom de voz e traduções anteriores supera sempre o mesmo modelo com cadeias de texto em bruto. O glossário garante que «Submit» seja traduzido da mesma forma em todas as páginas. O tom de voz mantém a formalidade consistente entre o francês e o alemão. As instruções personalizadas indicam ao modelo que «Stage» no vosso produto é uma etapa de pipeline, não um palco de teatro.
A memória de tradução é a parte que a maioria das ferramentas subestima. Cada edição manual é um sinal: é assim que o dizemos aqui. Um motor sério armazena essas edições, apresenta-as na próxima cadeia de texto semelhante e identifica padrões para que o modelo deixe de repetir as mesmas correções. Quanto mais tempo a memória funciona, menos trabalho tem o revisor. O modelo é substituível. A memória não.
Os avaliadores de qualidade são a rede de segurança que o motor sozinho não consegue fornecer. Preservação de variáveis, integridade de HTML, discrepâncias no glossário, limites de comprimento. Ativam-se automaticamente e detetam falhas que soam fluentes mas quebram o build. A análise da Translated.com assinala que o COMET atribui valores excessivamente generosos a traduções que soam bem mas são infiéis ao original (Translated.com, 2025). Os fornecedores que dependem apenas do COMET estão a ler o seu próprio reflexo.
Em termos de magnitude: a Smartling publicou o caso de um cliente Fortune 100 que poupou 3,4 milhões de dólares num ano e lançou 50 por cento mais rapidamente (Smartling, 2026). A Prismy inclui glossário, tom de voz, memória de tradução e avaliadores prontos a usar (motor de tradução com IA).
Os motores estão estandardizados. A dor real está na camada 2.
Camada 2: revisão, ao vivo e em contexto
O meu revisor passou três horas a reescrever a saída da IA num ficheiro JSON porque não havia forma de ver as cadeias de texto em contexto.
Superfície de revisão. Onde um não programador verifica e aperfeiçoa a saída da IA. A melhor é a própria aplicação em funcionamento.
A revisão ideal acontece ao vivo. Usa-se o próprio produto, deteta-se uma frase que soa estranha e corrige-se no momento. Sem ficheiro JSON, sem dashboard, sem nenhum programador no meio. Um overlay do Chrome na aplicação live é a expressão mais clara: cada cadeia de texto editável no seu lugar, com o ecrã circundante como contexto.
As edições ao vivo cobrem a longa cauda. Não cobrem o caso em que um revisor profissional revê quatrocentas cadeias de texto antes do lançamento. Esse trabalho precisa de um TMS. O estrangulamento aí é a perda de contexto: uma fila de cadeias de texto sem interface de utilizador à volta é impossível de traduzir bem.
A Prismy combina um TMS para o caso de volume elevado com pré-visualizações ao vivo de cada cadeia de texto na interface de utilizador real e capturas de ecrã automáticas obtidas da aplicação em execução. O formato de volume de que o revisor precisa, com o contexto que torna a edição boa.

O tempo médio de revisão de uma cadeia de texto gerida pela Prismy é de 15 minutos por língua, contra três ou mais horas quando o revisor reconstrói o contexto a partir de JSON em bruto. O número não tem a ver com velocidade de digitação. Tem a ver com não precisar de reconstruir onde cada cadeia de texto se encontra no produto antes de a formular.
Se a superfície de revisão está resolvida, fica a terceira questão: como é que a edição chega a produção?
Camada 3: colaboração, levar a alteração a produção de forma segura
O revisor fez vinte alterações na folha de cálculo e agora estou a colá-las no ficheiro JSON. Esqueci-me de uma chaveta de fecho e o build de staging está a vermelho.
Colaboração. O caminho desde «o revisor alterou os textos» até «a alteração está live em produção», sem que um programador tenha de a supervisionar.
Imagine o workflow da folha de cálculo. O revisor edita vinte cadeias de texto numa folha partilhada. Um programador ou PM cola-as na codebase. Uma linha recebe uma vírgula extra. Outra perde uma variável {userName}. O build quebra. Multiplicado por cada lançamento, cada língua, cada revisor.
A boa colaboração elimina esse ciclo. A edição do revisor chega como um pequeno pull request que o programador funde com um clique. Três coisas tornam isso possível:
- Segurança sintática. Validada automaticamente: variáveis preservadas, tags HTML fechadas, glossário respeitado, limites de comprimento cumpridos. Uma alteração que quebraria a aplicação nunca chega ao PR.
- Entrega via pull request. O PR mostra ao programador exatamente o que mudou, na mesma vista de diff que usa para o código. Consulte o workflow de localização com GitHub e a integração com GitLab.
- Atualizações over-the-air. Para produtos móveis e servidos via CDN, OTA significa que uma correção de texto às 17h de sexta-feira chega a produção antes do fim de semana sem um lançamento da aplicação.
Um cliente IoT em Série A reportou que os conflitos do GitHub em ficheiros de tradução passaram de um problema semanal para zero, poupando três a quatro dias por mês. A Crowdin publicou um caso de estudo da Polhus com 75 por cento de traduções geradas por IA aprovadas sem edições e uma poupança de cerca de 80.000 dólares (Crowdin, 2026).
Um programador nunca deveria passar uma tarde de terça-feira a colar cadeias de texto. Agora, a decisão de construir ou comprar.
Construir ou comprar: um quadro de decisão para a localização com IA
Compre se lança em duas ou mais línguas, tem dez ou mais engenheiros de produto e a sua localização é mais do que um dump de configuração. O custo de uma superfície de revisão ausente acumula-se com cada língua e persona que adiciona.
Construa se o seu modelo de segurança proíbe o acesso de terceiros (raro, muitas vezes resolvido por uma opção de modo alojado) ou tem um caso de uso regulamentado. Caso contrário, o custo de construir as três camadas é de seis a doze meses de atenção de um engenheiro, mais manutenção contínua.
O custo de comprar mal é mais comum do que o custo de comprar. Um TMS enterprise que ninguém usa. Uma CLI que o PM não consegue tocar. Um workflow de folhas de cálculo que quebra na quinta língua. A decisão não é «melhor ferramenta de tradução com IA». É «que workflow se adapta à minha equipa».
A opinião que este artigo defende: a qualidade da tradução com IA está resolvida. O produto real é o workflow. Escolha a ferramenta cuja superfície de revisão e fluxo de colaboração correspondem à forma como a sua equipa já trabalha, não a que tem a lista de funcionalidades mais longa. Se ainda está a avaliar ferramentas apenas pela qualidade do motor, está a responder à pergunta de ontem.
Uma auditoria de localização com IA de 15 minutos
Aplique isto ao seu próprio setup. Cada «não» é um ponto onde o seu programador acaba a fazer trabalho de localização que outra pessoa deveria fazer, ou onde um lançamento pára porque os textos não estão prontos.
A auditoria de 7 perguntas
Maioria de «não» = o seu stack está a custar-lhe horas de desenvolvimentoAutoavaliação rápida para responsáveis de engenharia de produto e localização.
- MotorTem um glossário que o PM pode editar sem abrir um ticket?
- MotorA sua ferramenta assinala variáveis quebradas, HTML em falta ou discrepâncias no glossário antes do merge?
- RevisãoO seu UX writer consegue rever textos dentro do Figma, em contexto com o design?
- RevisãoUm revisor nativo consegue aperfeiçoar uma cadeia de texto na aplicação live, sem tocar num ficheiro JSON?
- ColaboraçãoA sua ferramenta abre um PR do Git limpo para novas cadeias de texto, sem nenhum passo manual de cópia?
- ColaboraçãoQuando uma cadeia de texto em francês está errada às 17h de sexta-feira, um não programador consegue corrigi-la em produção sem incomodar o programador?
- EscalarA sua equipa consegue adicionar uma sexta língua sem aumentar os recursos humanos?
Maioria de «não»? A Prismy foi desenvolvida exatamente para isto. Ligue o GitHub ou o GitLab e lance o seu primeiro PR de tradução com IA no mesmo dia.
Descubra a Prismy →A pergunta sobre escalar não é teórica. Alexis, Figures: «De duas línguas para quase dez com uma consistência impecável.» Essa equipa passou de um setup ad hoc a duas línguas para um stack de produção com nove línguas sem adicionar nenhum papel de localização. Se o seu stack não consegue levá-lo até lá, tem um problema de workflow, não um problema de motor.
Perguntas frequentes
O que é a localização com IA?
A localização com IA é o uso de LLMs e avaliadores de qualidade para traduzir, adaptar e rever textos de produtos à velocidade dos lançamentos. Abrange o controlo do glossário, o tom de voz, a memória de tradução, a deteção de alucinações e a entrega segura para produção.
Em que se diferencia a localização com IA da tradução automática?
A tradução automática é o motor sozinho: texto de origem entra, texto de destino sai. A localização com IA é o motor mais o workflow: glossário, tom de voz, memória de tradução, superfícies de revisão e um caminho de colaboração Git-nativo ou OTA.
A tradução com IA é suficientemente boa para produção?
Para línguas de alta disponibilidade e textos de produto, sim, com avaliadores de qualidade e revisão humana. Para conteúdo jurídico, médico ou criativo, ainda não. A literatura de 2025 mostra paridade do motor nos pares mais comuns a par de pontos cegos em alucinações.
A IA pode substituir os tradutores humanos?
Não. A IA trata do volume de primeira passagem. Os humanos tratam das nuances, da revisão do tom de voz e do conteúdo de alto risco. A economia desloca-se da tradução para a revisão.
Quanto custa a localização com IA?
O custo do motor é de aproximadamente um a três cêntimos por cadeia de texto com um LLM de fronteira. A maior parte das poupanças face a um TMS está na revisão e na colaboração, não no modelo. Uma redução de 50 por cento nos custos totais é uma ordem de grandeza comum.
Qual é a melhor plataforma de localização com IA em 2026?
Não há uma resposta única. Motor-primeiro se tiver um orçamento para serviços geridos. Workflow-primeiro se lançar a partir do Git e precisar de ter PMs, UX writers e revisores no processo.
Não perca as nossas análises do setor!
Receba as últimas novidades sobre localização, traduções com IA e atualizações de produtos diretamente na sua caixa de entrada.
Sem spam, cancele a subscrição a qualquer momento. Respeitamos a sua privacidade.

Ir global, de forma simples e poderosa.

© 2026 Prismy. Todos os direitos reservados.