21/05/2026 · Industry
Qualità della localizzazione per i team SaaS: cosa verificare prima del rilascio
Il 73 % dei team SaaS scopre gli errori tramite segnalazioni degli utenti, non dalla QA. La qualità della localizzazione rileva variabili errate, HTML, glossario e lunghezza.

Un revisore madrelingua modifica una stringa tradotta dall'IA e rinomina
{userName}in{nomeUtente}. La variabile non viene più risolta. L'etichetta ora mostra{nomeUtente}in produzione per ogni utente francese. La revisione manuale l'ha approvata: il revisore leggeva per il significato. Un controllo automatizzato lo avrebbe rilevato in meno di un secondo.
Cosa significa davvero la qualità della localizzazione
La qualità della localizzazione è il processo di verifica che le traduzioni siano corrette prima che raggiungano gli utenti. Riguarda sia la garanzia di qualità della traduzione (il significato è accurato?) sia l'integrità strutturale (le variabili, i tag e i termini del glossario sono intatti?). Sono due compiti separati con due strumenti diversi: controlli automatizzati per gli errori strutturali e revisione umana per il giudizio linguistico.
La maggior parte dei team li confonde. Inviano le stringhe a un membro bilingue del team e lo considerano fatto. Il revisore rileva problemi di tono. Non rileva una variabile mancante perché legge per il significato, non eseguendo una corrispondenza di pattern.
I numeri lo confermano. Un sondaggio del 2026 su 1.000 team di ingegneria e prodotto ha rilevato che il 73 % scopre gli errori di traduzione in produzione tramite segnalazioni degli utenti (IntlPull, State of i18n 2026). Non dalla QA. Non dai test. Dai reclami degli utenti. Lo stesso sondaggio ha rilevato che il 52 % non ha alcun processo di QA sistematico al di là del controllo manuale a campione.
Il controllo manuale a campione non è un processo di QA. È una lotteria.
Gli errori strutturali sono quelli che vale la pena automatizzare. Ecco come si presentano.
I cinque tipi di controlli di QA della localizzazione
Ogni stringa di traduzione passa attraverso cinque controlli automatizzati prima che un revisore umano la veda. Ognuno rileva una classe di errori che la revisione manuale manca sistematicamente.
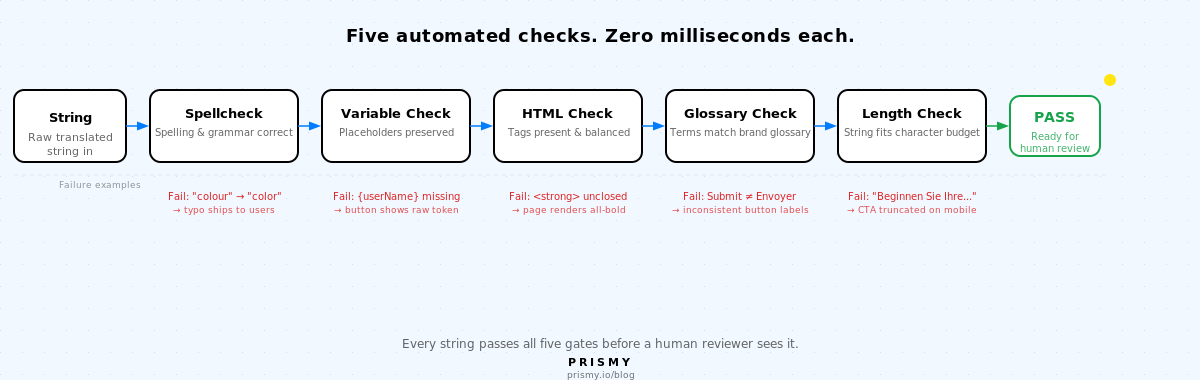
1. Controllo ortografico
Ogni chiave di traduzione deve essere priva di errori ortografici e grammaticali.
La modalità di errore: una stringa tradotta dall'IA o una modifica umana introduce un refuso, una forma verbale errata o un errore grammaticale che passa inosservato perché nessuno lo cerca esplicitamente. La revisione manuale ne rileva molti, ma i revisori che leggono per il significato mancano gli errori sottili, specialmente nelle lingue in cui non sono completamente fluenti.
Il controllo ortografico automatizzato viene eseguito su ogni chiave di traduzione in ogni locale prima che la stringa raggiunga un revisore. Segnala errori ortografici e problemi grammaticali di base in meno di un millisecondo, su scala, in ogni lingua in parallelo.
2. Preservazione delle variabili
Ogni segnaposto di interpolazione nella stringa sorgente deve apparire nella stringa tradotta con il formato corretto.
La modalità di errore: un revisore madrelingua modifica una stringa tradotta dall'IA e rinomina la variabile: {userName} diventa {nomeUtente}, oppure la omette completamente durante la riformulazione. La variabile non viene più risolta. In produzione, gli utenti vedono il segnaposto grezzo invece del loro nome. La traduzione IA gestisce correttamente questo; l'errore viene introdotto quando un umano modifica l'output senza rendersi conto che la variabile è essenziale.
Questo è automatizzabile con una semplice corrispondenza di pattern. Il controllo viene eseguito in meno di un millisecondo. Lo stesso sondaggio ha rilevato che il 61 % dei team ha riscontrato variabili segnaposto errate in produzione. Ognuno di quei fallimenti ha superato una revisione umana.
3. Integrità di HTML e tag
Ogni tag HTML nella stringa sorgente deve essere presente e bilanciato nella traduzione.
La modalità di errore: un traduttore lavora in modalità testo normale, o un sistema di traduzione automatica omette un tag di chiusura durante la ricostruzione della stringa. La sorgente dice Your subscription is <strong>active</strong>. La traduzione dice Il tuo abbonamento è <strong>attivo. Manca </strong>. Il resto della pagina viene renderizzato in grassetto.
I controlli automatizzati di bilanciamento dei tag rilevano questo. Il 41 % dei team ha inviato traduzioni errate che hanno interrotto il layout dell'interfaccia utente, secondo lo stesso sondaggio. La perdita di tag HTML è una delle cause principali.
4. Coerenza del glossario
Ogni termine nel glossario del brand deve apparire con la sua traduzione corretta in ogni lingua, in modo coerente in tutte le stringhe.
Senza un controllo del glossario, i traduttori prendono decisioni indipendenti a livello di parola. «Submit» diventa «Invia» in una stringa e «Pubblica» in un'altra. «Free trial» diventa «Prova gratuita» nella pagina dei prezzi e «Prova offerta» nel flusso di onboarding. Gli utenti lo notano. I ticket di supporto menzionano «il pulsante confuso».
Il 58 % dei team segnala terminologia errata e termini incoerenti come tipo di errore di produzione. La soluzione non sono traduttori migliori. È un glossario che il valutatore verifica su ogni stringa.
Il vero lavoro si fa sul glossario. Dobbiamo assicurarci che le traduzioni dei termini chiave siano corrette nella nuova lingua. È lì che trascorriamo la maggior parte del tempo.Alexis Toyane, Product Lead di Figures
Figures è passato da due lingue a nove. Il glossario non è stato il costo. Era il fondamento. Scoprite come ci sono arrivati: Figures ha scalato a nove lingue.
5. Lunghezza e overflow
La stringa tradotta deve adattarsi all'elemento dell'interfaccia utente che occuperà. Il testo tedesco è più lungo del 30-40 % rispetto all'inglese. Il giapponese può essere più corto ma richiede regole di altezza della riga diverse.
Nessuno verifica la lunghezza finché la stringa non è nell'app in esecuzione. Il TMS mostra la stringa grezza, non il pulsante renderizzato. Una call to action tedesca che dovrebbe leggere «Start your free trial» diventa «Beginnen Sie Ihre kostenlose...» e viene troncata al bordo del pulsante. Il CTA principale è invisibile in uno dei vostri mercati principali.
Il 67 % dei team ha riscontrato overflow del testo e troncamento in produzione. Impostare budget di caratteri per stringa e verificarli a livello di stringa rileva la coda lunga prima del rendering.
Perché la revisione manuale manca gli errori strutturali
Un revisore umano legge per il significato. Rileverà una mancata corrispondenza di tono, uno scivolone culturale, una frase che suona legnosa in portoghese. Non rileverà {userName} non risolto nella stringa perché lo legge inconsciamente come un valore compilato.
I revisori lavorano anche su scala: 20-50 stringhe all'ora è un ritmo realistico per una revisione attenta. Una release di 50 stringhe su cinque lingue significa 250 revisioni di stringhe. I controlli strutturali vengono eseguiti sulle stesse 250 stringhe in millisecondi.
I dati del sondaggio Common Sense Advisory del 2025 sono diretti: la QA automatizzata rileva il 70-80 % di tutti i problemi di traduzione, salendo al 90-94 % per i team con una rigorosa gestione del glossario. Il restante 6-30 % è linguistico e culturale e richiede giudizio umano. Questa è la divisione del lavoro.
Il calcolo dei costi lo chiude. Correggere un errore di traduzione dopo che raggiunge la produzione costa 8-12 volte di più che rilevarlo durante la traduzione (Nimdzi). Per un team che gestisce cinque lingue con due release al mese, quel calcolo cambia rapidamente.
Avete tre punti di partenza comuni:
Se siete su un processo manuale: il vostro revisore bilingue rileva il 20 % linguistico. L'80 % strutturale viene inviato. La variabile che il vostro revisore non ha notato è ora davanti a 2.000 utenti tedeschi.
Se siete su un TMS aziendale: la vostra scheda QA esiste, ma viene eseguita all'interno di una piattaforma. Se le stringhe vengono copiate fuori dal TMS prima della distribuzione, la scheda QA non le ha mai viste. Gli errori strutturali escono dalla porta sul retro.
Se siete su un CLI solo per sviluppatori: il vostro CI valida la sintassi del file. Non valida la preservazione delle variabili, l'integrità dei tag o la coerenza del glossario. Tali controlli richiedono la conoscenza del contenuto della stringa, non solo del suo formato.
Come si presenta un processo sistematico di QA della localizzazione
Un processo sistematico esegue i cinque controlli automatizzati in due momenti, poi aggiunge la revisione umana sopra:
Eseguite i cinque valutatori continuamente man mano che i testi vengono aggiornati. I controlli vengono eseguiti automaticamente in due posti. Quando vengono generate le traduzioni IA, il motore di traduzione IA di Prismy esegue controllo ortografico, preservazione delle variabili, integrità HTML, coerenza del glossario e controlli di lunghezza al momento della generazione: gli errori strutturali non entrano mai nei file di traduzione. Inline durante la modifica, nell'app web di Prismy e nell'estensione Chrome, gli editor vedono i problemi segnalati in tempo reale prima di confermare una modifica. Correggete prima del rilascio, non dopo.
Eseguite i valutatori una volta sui vostri testi esistenti quando impostate Prismy per la prima volta. La maggior parte dei team ha file di traduzione costruiti nel corso degli anni: stringhe scritte da esseri umani, copiate tra strumenti, modificate senza valutatori che guardano. Quel backlog ha variabili silenziosamente rotte, termini del glossario applicati in modo incoerente e lunghezze che traboccano su schermi che nessuno ha controllato. Un passaggio di audit una tantum fa emergere tutto questo prima di andare in produzione.
I valutatori di Prismy gestiscono entrambi i momenti automaticamente: controllo ortografico, verifica delle variabili, integrità HTML, corrispondenza del glossario e budget di lunghezza vengono eseguiti su ogni Pull Request Git-nativo e inline nell'editor. Per la qualità della traduzione IA che alimenta il processo a monte, consultate la guida completa.
-
Controllo ortograficoAutomatizzabileScegliete tre chiavi di traduzione dalle vostre locale più usate ed eseguitele attraverso uno strumento di controllo ortografico. I refusi e gli errori grammaticali che i revisori leggono oltre appaiono immediatamente.
-
Preservazione delle variabiliAutomatizzabileCercate nei vostri file tradotti qualsiasi
{,%o{{che appare nella sorgente ma non nella traduzione. Se ne trovate uno, il vostro processo di QA non lo ha rilevato. -
Integrità dei tag HTMLAutomatizzabileEseguite un controllo di bilanciamento dei tag su qualsiasi stringa tradotta che contenga HTML. Un
<strong>o<a>non chiuso in produzione cascaderà lo stile grassetto o link su un paragrafo. -
Coerenza del glossarioAutomatizzabileScegliete tre termini chiave del prodotto (il vostro CTA principale, il nome del vostro prodotto, il nome di una funzionalità). Verificate se vengono tradotti allo stesso modo in ogni stringa in ogni lingua. In caso contrario, avete bisogno di un controllo del glossario nel vostro valutatore.
-
Lunghezza e overflowAutomatizzabileCaricate il vostro prodotto in tedesco o in un'altra lingua con espansione lunga. Controllate ogni pulsante ed etichetta per il troncamento. Se qualcosa viene troncato, i vostri budget di caratteri non vengono verificati al momento della QA.
FAQ
Qual è la differenza tra QA della localizzazione e revisione della traduzione?
La revisione della traduzione è una verifica umana della qualità: tono, accuratezza, fluidità. La qualità della localizzazione include questo, più controlli meccanici automatizzati: ortografia, variabili, HTML, glossario, lunghezza. La QA dovrebbe essere eseguita prima della revisione umana, non al suo posto. Lo strato automatizzato elimina gli errori strutturali in modo che il revisore umano si concentri sul giudizio.
Come si testa la localizzazione prima del rilascio?
Quattro passaggi: valutatori automatizzati su ogni Pull Request (ortografia, variabili, HTML, glossario, lunghezza), revisione umana nel contesto nell'app in esecuzione, un test di fumo di rilascio leggero su una lingua e un audit trimestrale del glossario per mantenere i controlli automatizzati aggiornati con la terminologia del vostro prodotto. Un solido processo di QA della traduzione include anche test di localizzazione in contesti reali di dispositivi/schermo per rilevare problemi di overflow e rendering che i controlli a livello di stringa non colgono.
Cosa causa i fallimenti nella garanzia di qualità della traduzione in produzione?
Di solito non il traduttore. Di solito il processo. Le variabili mancanti si infiltrano quando i traduttori lavorano in testo normale senza valutatori che guardano. La deriva del glossario si verifica quando nessun controllo impone la terminologia. L'overflow di lunghezza si verifica quando nessuno testa le stringhe renderizzate in un'interfaccia utente reale. La maggior parte degli errori di traduzione di produzione sono strutturali, non linguistici, e la maggior parte degli errori strutturali è automatizzabile.
Gli strumenti automatizzati possono sostituire la revisione della traduzione umana?
Per gli errori strutturali (ortografia, variabili, HTML, glossario, lunghezza): sì, e lo fanno in modo più coerente e veloce di un essere umano. Per il giudizio linguistico (tono, adattamento culturale, sfumatura): no. Un processo completo di QA della localizzazione usa entrambi: i controlli automatizzati eliminano i fallimenti meccanici, la revisione umana rileva quelli linguistici. Il tasso di rilevamento automatizzato del 70-94 % lascia il 6-30 % su cui i revisori umani si concentrano.
Non perda le nostre analisi di settore!
Riceva le ultime novità su localizzazione, traduzioni con IA e aggiornamenti di prodotto direttamente nella Sua casella di posta.
Niente spam, annulli l'iscrizione in qualsiasi momento. Rispettiamo la Sua privacy.

Vai globale, in modo semplice e potente.
