29 avril 2026 · Industry
Localisation IA en 2026 : moteur, révision et collaboration
La localisation IA va au-delà du modèle. Trois couches : moteur, révision et collaboration. Un guide workflow-first pour les équipes SaaS en 2026.

Un PM veut affiner le wording d'une feature en prod. Il fouille un fichier JSON pour retrouver les clés, dérange un dev pour pousser une preprod, itère sur la formulation, relance la traduction dans cinq langues, attend un nouveau déploiement. Une demi-journée pour deux mots. Le moteur a fait sa part en quelques secondes. Le workflow autour de lui est le vrai problème. À la fin de ce guide, vous aurez une carte à trois couches d'un stack de localisation IA et un audit de 15 minutes que vous pourrez appliquer à votre propre setup demain.
Ce que « localisation IA » signifie vraiment en 2026
La localisation IA est l'utilisation de grands modèles de langage et d'évaluateurs de qualité pour traduire, adapter et réviser les textes produits à la vitesse des releases. C'est plus que de la traduction. Un stack de localisation IA fonctionnel gère le contrôle du glossaire, la voix de marque, la détection des hallucinations et le chemin qui amène les nouvelles chaînes en production.
Le moteur a franchi un vrai seuil. Une méta-évaluation de 2025 a montré que les métriques actuelles atteignent ou dépassent les niveaux d'accord des évaluateurs humains pour les paires de langues à haute disponibilité (arxiv 2506.19571, juin 2025). Le même article note que COMET attribue des scores généreux aux hallucinations fluentes : le moteur est assez bon pour être mis en production, mais pas assez bon pour être laissé sans surveillance.
Les données de marché racontent la même histoire. Le secteur des services linguistiques et des technologies a généré 49,68 milliards de dollars en 2023, soit une baisse de 4,5 % d'une année sur l'autre, avec l'IA générative citée comme facteur (CSA Research, 2024). Le travail se fait. La question est de savoir qui l'orchestre. Pour une perspective plus large, consultez notre analyse de la qualité des traductions IA en production.
Si le moteur est résolu, où se situe la vraie douleur ? Dans trois couches.
Le stack à trois couches : moteur, révision et collaboration
Chaque outil de localisation IA, du script Python maison à la plateforme enterprise, peut être cartographié sur trois couches.
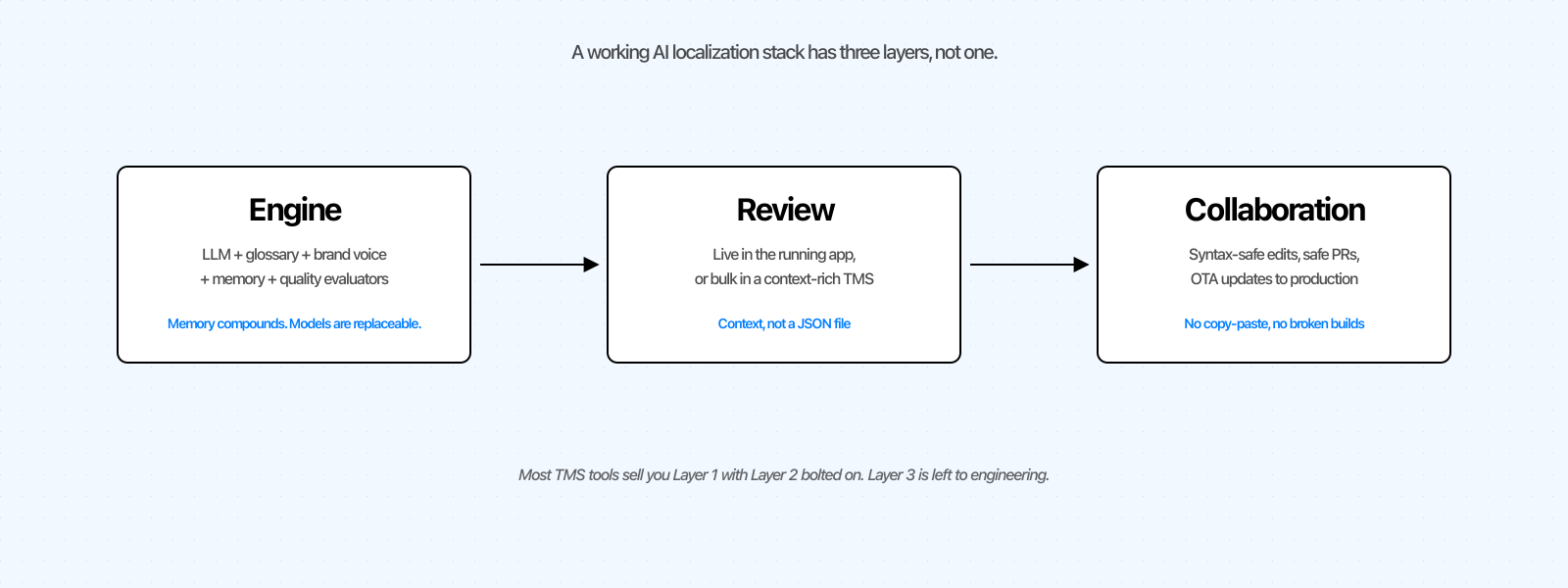
Moteur. Le modèle, plus le glossaire, la voix de marque, les instructions personnalisées, la mémoire de traduction et les évaluateurs de qualité. Largement standardisé, avec une nuance : la mémoire s'accumule, les modèles non.
Révision. Là où un humain vérifie et affine l'output de l'IA. La plupart des outils ont été créés avant l'IA, quand les traducteurs travaillaient depuis des tableurs avant que la feature soit livrée. Le pattern moderne est IA-d'abord : traduction automatique, puis révision en contexte.
Collaboration. Comment une modification de texte passe de la révision à la production en toute sécurité. La mauvaise collaboration, c'est un développeur qui colle des chaînes dans un fichier JSON à 23 h. La bonne collaboration, c'est la modification qui arrive en production sans erreur de syntaxe et sans déranger les personnes qui n'avaient pas besoin d'être dans la boucle.
Si vous veniez d'un tableur, vous avez la couche 1 en DIY et rien d'autre. Si vous veniez de Lokalise ou Crowdin, vous avez les couches 1 et 2 dans un seul produit, mais une couche 3 pilotée par la synchronisation. Si vous veniez de Lingo.dev ou Languine, vous avez une couche 1 solide, une CLI pour la couche 3 et pas de vraie couche 2 pour les non-développeurs.
Le bon outil dépend de votre point de départ. Parcourons chaque couche.
Couche 1 : le moteur, largement résolu
Le modèle importe moins que le contexte qu'il reçoit. Un LLM frontier avec un glossaire, un profil de voix de marque et des traductions antérieures bat le même modèle avec des chaînes brutes à chaque fois. Le glossaire garantit que « Submit » est rendu de la même façon sur chaque page. La voix de marque maintient la formalité cohérente entre le français et l'allemand. Les instructions personnalisées indiquent au modèle que « Stage » dans votre produit est une étape de pipeline, pas une scène de théâtre.
La mémoire de traduction est la partie que la plupart des outils sous-estiment. Chaque modification manuelle est un signal : c'est comme ça qu'on le dit ici. Un moteur sérieux stocke ces modifications, les affiche à la prochaine chaîne similaire et identifie les patterns pour que le modèle arrête de répéter les mêmes corrections. Plus la mémoire tourne longtemps, moins le relecteur a de travail. Le modèle est remplaçable. La mémoire non.
Les évaluateurs de qualité sont le filet de sécurité que le moteur seul ne peut pas fournir. Préservation des variables, intégrité HTML, écarts de glossaire, budgets de longueur. Ils se déclenchent automatiquement et capturent les erreurs qui sonnent fluent mais cassent le build. L'analyse de Translated.com note que COMET attribue des valeurs excessivement généreuses aux traductions confiantes mais infidèles (Translated.com, 2025). Les fournisseurs qui s'appuient uniquement sur COMET lisent leur propre reflet.
En ordre de grandeur : Smartling a publié le cas d'un client Fortune 100 qui a économisé 3,4 millions de dollars en un an et livré 50 % plus vite (Smartling, 2026). Prismy fournit glossaire, voix de marque, mémoire de traduction et évaluateurs prêts à l'emploi (moteur de traduction IA).
Les moteurs sont standardisés. La vraie douleur se trouve dans la couche 2.
Couche 2 : révision, en direct et en contexte
Mon relecteur a passé trois heures à réécrire l'output de l'IA dans un fichier JSON parce qu'il n'y avait aucun moyen de voir les chaînes en contexte.
Surface de révision. Là où un non-développeur vérifie et affine l'output de l'IA. La meilleure est l'application elle-même en cours d'exécution.
La révision idéale se fait en direct. Vous utilisez votre propre produit, vous repérez une formulation qui sonne faux, vous la corrigez sur-le-champ. Pas de fichier JSON, pas de tableau de bord, pas de développeur dans la boucle. Un overlay Chrome sur l'application live est l'expression la plus épurée : chaque chaîne modifiable à sa place, avec l'écran environnant comme contexte.
Les modifications en direct couvrent la longue traîne. Elles ne couvrent pas le cas où un correcteur professionnel révise quatre cents chaînes avant un lancement. Ce travail a besoin d'un TMS. Le goulot d'étranglement est la perte de contexte : une rangée de chaînes sans interface autour est impossible à bien traduire.
Prismy associe un TMS pour le cas de révision en volume à des aperçus en direct de chaque chaîne dans l'interface réelle, et des captures d'écran automatiques récupérées depuis l'application en cours. Le format en volume dont le correcteur a besoin, avec le contexte qui rend la modification bonne.

Le temps de révision moyen d'une chaîne gérée par Prismy est de 15 minutes par langue, contre trois heures ou plus quand le relecteur reconstruit le contexte depuis le JSON brut. Le chiffre ne concerne pas la vitesse de frappe. Il concerne le fait de ne pas avoir à reconstituer où se trouve chaque chaîne dans le produit avant de la formuler.
Si la surface de révision est résolue, la troisième question reste : comment la modification arrive-t-elle en production ?
Couche 3 : collaboration, amener la modification en production en toute sécurité
Le relecteur a fait vingt modifications dans le tableur et maintenant je les colle dans le fichier JSON. J'ai oublié une accolade fermante et le build de staging est au rouge.
Collaboration. Le chemin de « le relecteur a changé les textes » à « la modification est live en production », sans qu'un développeur ait à la surveiller.
Imaginez le workflow du tableur. Le relecteur modifie vingt chaînes dans un tableur partagé. Un développeur ou PM les copie-colle dans la codebase. Une ligne reçoit une virgule en trop. Une autre perd une variable {userName}. Le build se casse. Multiplié par chaque release, chaque langue, chaque relecteur.
La bonne collaboration supprime cette boucle. La modification du relecteur arrive sous forme d'une petite Pull Request que le développeur merge en un clic. Trois choses le rendent possible :
- Sécurité syntaxique. Validée automatiquement : variables préservées, balises HTML fermées, glossaire respecté, budgets de longueur honorés. Une modification qui casserait l'application n'atteint jamais la PR.
- Remise via Pull Request. La PR montre au développeur exactement ce qui a changé, dans la même vue de diff qu'il utilise pour le code. Consultez le workflow de localisation GitHub et l'intégration GitLab.
- Mises à jour over-the-air. Pour les produits mobiles et servis par CDN, OTA signifie qu'une correction de texte à 17 h le vendredi est en production avant le week-end sans release d'application.
Un client IoT en Série A a rapporté que les conflits GitHub sur les fichiers de traduction sont passés d'un problème hebdomadaire à zéro, économisant trois à quatre jours par mois. Crowdin a publié une étude de cas Polhus avec 75 % de traductions générées par IA approuvées sans modifications et environ 80 000 dollars économisés (Crowdin, 2026).
Un développeur ne devrait jamais passer un mardi après-midi à coller des chaînes. Maintenant, la décision de construire ou d'acheter.
Construire ou acheter : un cadre de décision pour la localisation IA
Achetez si vous livrez dans deux langues ou plus, avez dix ingénieurs produit ou plus et que votre localisation est plus qu'un dump de configuration. Le coût d'une surface de révision manquante s'accumule avec chaque langue et persona que vous ajoutez.
Construisez si votre modèle de sécurité interdit l'accès de tiers (rare, souvent résolu par une option de mode hébergé) ou si vous avez un cas d'usage réglementé. Sinon, le coût de la construction des trois couches est de six à douze mois d'attention d'un ingénieur, plus la maintenance continue.
Le coût d'un mauvais achat est plus fréquent que le coût d'un achat. Un TMS enterprise que personne n'utilise. Une CLI que le PM ne peut pas toucher. Un workflow de tableur qui se casse à la cinquième langue. La décision n'est pas « meilleur outil de traduction IA ». C'est « quel workflow correspond à mon équipe ».
L'opinion que cet article défend : la qualité de la traduction IA est résolue. Le vrai produit est le workflow. Choisissez l'outil dont la surface de révision et le flux de collaboration correspondent à la façon dont votre équipe travaille déjà, pas celui avec la plus longue liste de fonctionnalités. Si vous évaluez encore les outils uniquement sur la qualité du moteur, vous répondez à la question d'hier.
Un audit de localisation IA de 15 minutes
Appliquez ceci à votre propre setup. Chaque « non » est un endroit où votre développeur finit par faire un travail de localisation que quelqu'un d'autre devrait faire, ou où une release est bloquée parce que les textes ne sont pas prêts.
L'audit en 7 questions
Majorité de « non » = votre stack vous coûte des heures de développementAuto-évaluation rapide pour les responsables d'ingénierie produit et de localisation.
- MoteurAvez-vous un glossaire que le PM peut modifier sans ouvrir un ticket ?
- MoteurVotre outil signale-t-il les variables cassées, le HTML manquant ou les écarts de glossaire avant le merge ?
- RévisionVotre UX writer peut-il réviser les textes dans Figma, en contexte avec le design ?
- RévisionUn relecteur natif peut-il affiner une chaîne dans l'application live, sans toucher à un fichier JSON ?
- CollaborationVotre outil ouvre-t-il une Pull Request Git propre pour les nouvelles chaînes, sans étape manuelle de copier-coller ?
- CollaborationQuand une chaîne en allemand est fausse le vendredi à 17 h, un non-développeur peut-il la corriger en production sans déranger le développeur ?
- Mise à l'échelleVotre équipe peut-elle ajouter une sixième langue sans recruter ?
Majorité de « non » ? Prismy a été conçu exactement pour ça. Connectez GitHub ou GitLab et livrez votre première Pull Request de traduction IA le jour même.
Découvrir Prismy →La question de mise à l'échelle n'est pas théorique. Alexis, Figures : « De deux langues à presque dix avec une cohérence remarquable. » Cette équipe est passée d'un setup ad hoc à deux langues à un stack de production à neuf langues, sans ajouter de rôle de localisation. Si votre stack ne peut pas vous y amener, vous avez un problème de workflow, pas un problème de moteur.
FAQ
Qu'est-ce que la localisation IA ?
La localisation IA est l'utilisation de LLMs et d'évaluateurs de qualité pour traduire, adapter et réviser les textes produits à la vitesse des releases. Elle couvre le contrôle du glossaire, la voix de marque, la mémoire de traduction, la détection des hallucinations et la remise sécurisée en production.
En quoi la localisation IA diffère-t-elle de la traduction automatique ?
La traduction automatique, c'est le moteur seul : source en entrée, cible en sortie. La localisation IA, c'est le moteur plus le workflow : glossaire, voix de marque, mémoire de traduction, surfaces de révision et un chemin de collaboration Git-natif ou OTA.
La traduction IA est-elle assez bonne pour la production ?
Pour les langues à haute disponibilité et les textes produits, oui, avec des évaluateurs de qualité et une révision humaine par-dessus. Pour les contenus juridiques, médicaux ou créatifs, pas encore. La littérature de 2025 montre la parité du moteur sur les paires courantes avec des angles morts sur les hallucinations.
L'IA peut-elle remplacer les traducteurs humains ?
Non. L'IA gère le volume de première passe. Les humains gèrent les nuances, la révision de la voix de marque et les contenus à fort enjeu. L'économie passe de la traduction à la révision.
Combien coûte la localisation IA ?
Le coût du moteur est d'environ un à trois centimes par chaîne avec un LLM frontier. La plupart des économies par rapport à un TMS se trouvent dans la révision et la collaboration, pas dans le modèle. Une réduction de 50 % des dépenses totales est un ordre de grandeur courant.
Quelle est la meilleure plateforme de localisation IA en 2026 ?
Pas de réponse unique. Moteur-d'abord si vous avez un budget de services gérés. Workflow-d'abord si vous livrez depuis Git et avez besoin de PMs, UX writers et relecteurs dans la boucle.
Ne manquez pas nos insights !
Recevez les directement dans votre boîte mail.
Pas de spam, désabonnement possible à tout moment. Nous respectons votre vie privée.

Développez-vous à l'international en toute simplicité.

© 2026 Prismy. Tous droits réservés.