21 mai 2026 · Industry
Assurance qualité de la localisation pour les équipes SaaS : ce qu'il faut vérifier avant de livrer
73 % des équipes SaaS découvrent les erreurs via les utilisateurs, pas par la QA. L'assurance qualité de la localisation détecte les variables cassées, HTML, glossaire et longueur.

Un relecteur natif corrige une chaîne traduite par IA et renomme
{userName}en{nomUtilisateur}. La variable ne se résout plus. Le libellé affiche maintenant{nomUtilisateur}en production pour tous les utilisateurs français. La révision manuelle l'a validée : le relecteur lisait pour le sens. Un contrôle automatisé l'aurait détecté en moins d'une seconde.
Ce que signifie réellement l'assurance qualité de la localisation
L'assurance qualité de la localisation est le processus de vérification de la correction des traductions avant qu'elles n'atteignent les utilisateurs : cela couvre à la fois l'assurance qualité de la traduction (le sens est-il exact ?) et l'intégrité structurelle (les variables, les balises et les termes du glossaire sont-ils intacts ?). Ce sont deux tâches distinctes avec deux outils différents : des contrôles automatisés pour les erreurs structurelles, et une révision humaine pour le jugement linguistique.
La plupart des équipes les confondent. Elles envoient les chaînes à un membre de l'équipe bilingue et considèrent que c'est fait. Le relecteur détecte les problèmes de ton. Il ne détecte pas une variable manquante parce qu'il lit pour le sens, pas pour exécuter une correspondance de motif.
Les chiffres le confirment. Une enquête de 2026 auprès de 1 000 équipes d'ingénierie et de produit a révélé que 73 % découvrent les erreurs de traduction en production via les signalements des utilisateurs (IntlPull, State of i18n 2026). Pas par la QA. Pas par les tests. Par les plaintes des utilisateurs. La même enquête a révélé que 52 % n'ont aucun processus de QA systématique au-delà du contrôle ponctuel manuel.
Le contrôle ponctuel manuel n'est pas un processus de QA. C'est une loterie.
Les erreurs structurelles sont celles qui méritent d'être automatisées. Voici à quoi elles ressemblent.
Les cinq types de contrôles de QA de la localisation
Chaque chaîne de traduction passe par cinq contrôles automatisés avant qu'un relecteur humain ne la voie. Chacun détecte une classe d'échec que la révision manuelle manque systématiquement.
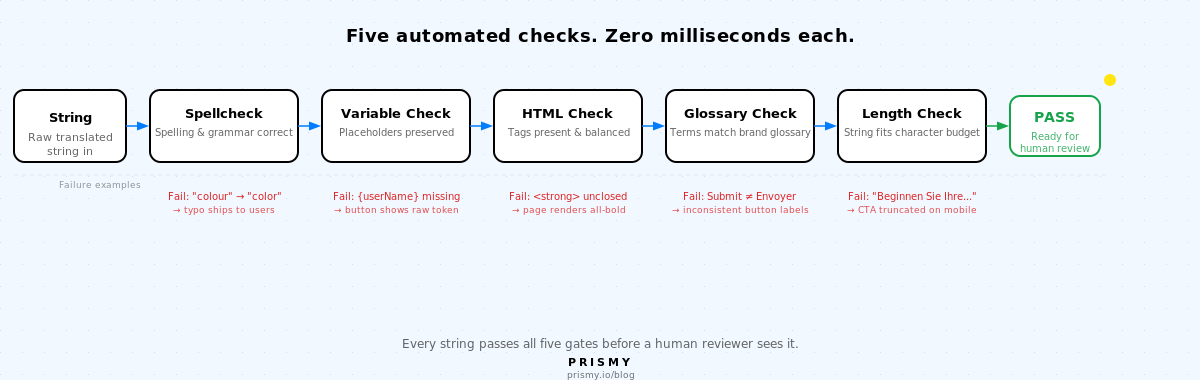
1. Vérification orthographique
Chaque clé de traduction doit être exempte d'erreurs d'orthographe et de grammaire.
Le mode d'échec : une chaîne traduite par IA ou une modification humaine introduit une faute de frappe, une forme verbale incorrecte ou une erreur grammaticale qui passe inaperçue parce que personne ne la cherche explicitement. La révision manuelle en détecte beaucoup, mais les relecteurs qui lisent pour le sens manquent les erreurs subtiles, en particulier dans les langues qu'ils ne maîtrisent pas complètement.
La vérification orthographique automatisée s'exécute sur chaque clé de traduction dans chaque locale avant que la chaîne n'atteigne un relecteur. Elle signale les erreurs d'orthographe et les problèmes de grammaire de base en moins d'une milliseconde, à grande échelle, sur chaque langue en parallèle.
2. Préservation des variables
Chaque espace réservé d'interpolation dans la chaîne source doit apparaître dans la chaîne traduite, avec le format correct.
Le mode d'échec : un relecteur natif corrige une chaîne traduite par IA et renomme la variable : {userName} devient {nomUtilisateur}, ou il la supprime entièrement lors de la reformulation. La variable ne se résout plus. En production, les utilisateurs voient l'espace réservé brut au lieu de leur nom. La traduction IA gère cela correctement ; l'erreur est introduite lorsqu'un humain modifie la sortie sans réaliser que la variable est porteuse.
Ceci est automatisable avec une simple correspondance de motif. Le contrôle s'exécute en moins d'une milliseconde. La même enquête a révélé que 61 % des équipes ont subi des variables d'espace réservé cassées en production. Chacun de ces échecs a passé une révision humaine.
3. Intégrité HTML et des balises
Chaque balise HTML dans la chaîne source doit être présente et équilibrée dans la traduction.
Le mode d'échec : un traducteur travaille en mode texte brut, ou un système de traduction automatique supprime une balise de fermeture lors de la reconstruction de la chaîne. La source indique Your subscription is <strong>active</strong>. La traduction indique Votre abonnement est <strong>actif. Manque </strong>. Le reste de la page s'affiche en gras.
Les contrôles automatisés d'équilibre des balises détectent cela. 41 % des équipes ont livré des traductions cassées qui ont brisé la mise en page de l'interface utilisateur, selon la même enquête. La perte de balises HTML est l'une des principales causes.
4. Cohérence du glossaire
Chaque terme du glossaire de marque doit apparaître avec sa traduction correcte dans chaque langue, de manière cohérente sur toutes les chaînes.
Sans contrôle du glossaire, les traducteurs prennent des décisions indépendantes au niveau des mots. « Submit » devient « Soumettre » dans une chaîne et « Envoyer » dans une autre. « Free trial » devient « Essai gratuit » sur la page de tarification et « Essai offert » dans le flux d'onboarding. Les utilisateurs le remarquent. Les tickets d'assistance mentionnent « le bouton déroutant ».
58 % des équipes signalent une terminologie incorrecte et des termes incohérents comme type d'erreur de production. La solution n'est pas de meilleurs traducteurs. C'est un glossaire que l'évaluateur vérifie sur chaque chaîne.
Le vrai travail se fait sur le glossaire. Nous devons nous assurer que les traductions des termes clés sont correctes dans la nouvelle langue. C'est là que nous passons le plus de temps.Alexis Toyane, Product Lead chez Figures
Figures est passé de deux langues à neuf. Le glossaire n'était pas la charge. C'était la fondation. Découvrez comment ils y sont parvenus : Figures est passé à neuf langues.
5. Longueur et débordement
La chaîne traduite doit s'adapter à l'élément d'interface utilisateur qu'elle occupera. Le texte allemand est 30 à 40 % plus long que l'anglais. Le japonais peut être plus court mais nécessiter des règles de hauteur de ligne différentes.
Personne ne vérifie la longueur tant que la chaîne n'est pas dans l'application en cours d'exécution. Le TMS affiche la chaîne brute, pas le bouton rendu. Un appel à l'action allemand qui devrait indiquer « Start your free trial » devient « Beginnen Sie Ihre kostenlose... » et est coupé à la bordure du bouton. Le CTA principal est invisible dans l'un de vos principaux marchés.
67 % des équipes ont subi un débordement de texte et une troncation en production. La définition de budgets de caractères par chaîne et leur vérification au niveau de la chaîne détecte la longue traîne avant le rendu.
Pourquoi la révision manuelle manque les erreurs structurelles
Un relecteur humain lit pour le sens. Il détectera une inadéquation de ton, un glissement culturel, une phrase qui sonne creux en portugais. Il ne détectera pas {userName} assis non résolu dans la chaîne parce qu'il le lit inconsciemment comme une valeur remplie.
Les relecteurs travaillent également à grande échelle : 20 à 50 chaînes par heure est un rythme réaliste pour une révision minutieuse. Une version de 50 chaînes sur cinq langues signifie 250 révisions de chaînes. Les contrôles structurels s'exécutent sur les mêmes 250 chaînes en millisecondes.
Les données de l'enquête Common Sense Advisory de 2025 sont directes : la QA automatisée détecte 70 à 80 % de tous les problèmes de traduction, passant à 90 à 94 % pour les équipes avec une gestion stricte du glossaire. Les 6 à 30 % restants sont linguistiques et culturels, nécessitant un jugement humain. C'est la division du travail.
Le calcul des coûts le confirme. La correction d'une erreur de traduction après avoir atteint la production coûte 8 à 12 fois plus cher que de la détecter pendant la traduction (Nimdzi). Pour une équipe gérant cinq langues avec deux versions par mois, ce calcul change rapidement.
Vous avez trois points de départ courants :
Si vous êtes sur un processus manuel : votre relecteur bilingue détecte les 20 % linguistiques. Les 80 % structurels sont livrés. La variable que votre relecteur n'a pas remarquée est maintenant devant 2 000 utilisateurs allemands.
Si vous êtes sur un TMS d'entreprise : votre onglet QA existe, mais il s'exécute à l'intérieur d'une plateforme. Si les chaînes sont copiées-collées hors du TMS avant le déploiement, l'onglet QA ne les a jamais vues. Les erreurs structurelles sortent par la porte latérale.
Si vous êtes sur un CLI pour développeurs uniquement : votre CI valide la syntaxe du fichier. Il ne valide pas la préservation des variables, l'intégrité des balises ou la cohérence du glossaire. Ces contrôles nécessitent une connaissance du contenu de la chaîne, pas seulement de son format.
À quoi ressemble un processus systématique de QA de la localisation
Un processus systématique exécute les cinq contrôles automatisés à deux moments, puis ajoute la révision humaine par-dessus :
Exécutez les cinq évaluateurs en continu à mesure que les textes sont mis à jour. Les contrôles s'exécutent automatiquement à deux endroits. Lorsque les traductions IA sont générées, le moteur de traduction IA de Prismy exécute la vérification orthographique, la préservation des variables, l'intégrité HTML, la cohérence du glossaire et les contrôles de longueur au moment de la génération : les erreurs structurelles n'entrent jamais dans les fichiers de traduction. En ligne lors de l'édition, dans l'application web Prismy et dans l'extension Chrome, les éditeurs voient les problèmes signalés en temps réel avant de valider une modification. Corrigez-le avant de livrer, pas après.
Exécutez les évaluateurs une fois sur vos textes existants lorsque vous configurez Prismy pour la première fois. La plupart des équipes ont des fichiers de traduction construits au fil des années : des chaînes écrites par des humains, copiées-collées entre les outils, éditées sans que les évaluateurs ne surveillent. Ce backlog contient des variables discrètement cassées, des termes du glossaire appliqués de manière incohérente et des longueurs qui débordent sur des écrans que personne n'a vérifiés. Un passage d'audit ponctuel fait remonter tout cela avant que vous ne passiez en production.
Les évaluateurs de Prismy gèrent automatiquement les deux moments : vérification orthographique, contrôle des variables, intégrité HTML, correspondance du glossaire et budget de longueur s'exécutent sur chaque Pull Request Git-native et en ligne dans l'éditeur. Pour la qualité de traduction IA qui alimente le processus en amont, consultez le guide complet.
-
Vérification orthographiqueAutomatisableChoisissez trois clés de traduction parmi vos locales les plus utilisées et exécutez-les via un outil de vérification orthographique. Les fautes de frappe et les erreurs grammaticales que les relecteurs lisent au-delà apparaissent immédiatement.
-
Préservation des variablesAutomatisableRecherchez dans vos fichiers traduits tout
{,%ou{{qui apparaît dans la source mais pas dans la traduction. Si vous en trouvez un, votre processus de QA ne l'a pas détecté. -
Intégrité des balises HTMLAutomatisableExécutez un contrôle d'équilibre des balises sur toutes les chaînes traduites contenant du HTML. Un
<strong>ou<a>non fermé en production va cascader le style gras ou lien sur un paragraphe. -
Cohérence du glossaireAutomatisableChoisissez trois termes de produit clés (votre CTA principal, le nom de votre produit, un nom de fonctionnalité). Vérifiez s'ils sont traduits de la même manière dans chaque chaîne sur chaque langue. Sinon, vous avez besoin d'un contrôle de glossaire dans votre évaluateur.
-
Longueur et débordementAutomatisableChargez votre produit en allemand ou dans une autre langue à longue expansion. Vérifiez chaque bouton et étiquette pour la troncation. Si quelque chose est coupé, vos budgets de caractères ne sont pas vérifiés au moment de la QA.
FAQ
Quelle est la différence entre la QA de localisation et la révision de traduction ?
La révision de traduction est une vérification humaine de la qualité : ton, exactitude, fluidité. L'assurance qualité de la localisation inclut cela, plus des contrôles mécaniques automatisés : vérification orthographique, variables, HTML, glossaire, longueur. La QA doit s'exécuter avant la révision humaine, pas à la place. La couche automatisée élimine les erreurs structurelles afin que le relecteur humain se concentre sur le jugement.
Comment tester la localisation avant la version ?
Quatre étapes : évaluateurs automatisés sur chaque Pull Request (vérification orthographique, variables, HTML, glossaire, longueur), révision humaine en contexte dans l'application en cours d'exécution, un test de fumée de version léger sur une langue, et un audit de glossaire trimestriel pour maintenir les contrôles automatisés à jour avec la terminologie de votre produit. Un processus solide de QA de traduction inclut également des tests de localisation dans des contextes réels d'appareil/écran pour détecter les problèmes de débordement et de rendu que les contrôles au niveau de la chaîne manquent.
Qu'est-ce qui cause les échecs d'assurance qualité de la traduction en production ?
Généralement pas le traducteur. Généralement le processus. Les variables manquantes passent lorsque les traducteurs travaillent en texte brut sans que les évaluateurs surveillent. La dérive du glossaire se produit lorsqu'aucun contrôle n'applique la terminologie. Le débordement de longueur se produit lorsque personne ne teste les chaînes rendues dans une interface utilisateur réelle. La plupart des erreurs de traduction de production sont structurelles, pas linguistiques, et la plupart des erreurs structurelles sont automatisables.
Les outils automatisés peuvent-ils remplacer la révision de traduction humaine ?
Pour les erreurs structurelles (vérification orthographique, variables, HTML, glossaire, longueur) : oui, et ils le font de manière plus cohérente et plus rapide qu'un humain. Pour le jugement linguistique (ton, adéquation culturelle, nuance) : non. Un processus complet de QA de la localisation utilise les deux : les contrôles automatisés éliminent les échecs mécaniques, la révision humaine détecte les échecs linguistiques. Le taux de détection automatisé de 70 à 94 % laisse 6 à 30 % sur lesquels les relecteurs humains doivent se concentrer.
Ne manquez pas nos insights !
Recevez les directement dans votre boîte mail.
Pas de spam, désabonnement possible à tout moment. Nous respectons votre vie privée.

Développez-vous à l'international en toute simplicité.

© 2026 Prismy. Tous droits réservés.