21/05/2026 · Industry
Control de calidad de localización para equipos SaaS: qué verificar antes de lanzar
El 73 % de los equipos SaaS descubren errores mediante informes de usuarios, no por control de calidad. Aprenda cómo el control de calidad de localización detecta variables rotas, HTML, glosario y longitud.

Un revisor nativo edita una cadena traducida por IA y renombra
{userName}como{nombreUsuario}. La variable ya no se resuelve. El elemento ahora muestra{nombreUsuario}en producción para todos los usuarios franceses. La revisión manual lo aprobó: el revisor leía para comprender el significado. Una verificación automatizada lo habría detectado en menos de un segundo.
Qué significa realmente el control de calidad de localización
El control de calidad de localización es el proceso de verificar que las traducciones son correctas antes de que lleguen a los usuarios. Abarca tanto la garantía de calidad de traducción (¿es el significado preciso?) como la integridad estructural (¿las variables, etiquetas y términos del glosario están intactos?). Son dos tareas separadas con dos herramientas diferentes: verificaciones automatizadas para errores estructurales y revisión humana para el juicio lingüístico.
La mayoría de los equipos los confunden. Envían cadenas a un miembro bilingüe del equipo y lo consideran terminado. El revisor detecta problemas de tono. No detecta una variable faltante porque está leyendo para comprender el significado, no ejecutando una coincidencia de patrones.
Los números lo confirman. Una encuesta de desarrolladores de 2026 realizada a 1.000 equipos de ingeniería y producto reveló que el 73 % descubre errores de traducción en producción a través de informes de usuarios (IntlPull, State of i18n 2026). No mediante control de calidad. No mediante pruebas. Mediante quejas de usuarios. La misma encuesta reveló que el 52 % no tiene ningún proceso de control de calidad sistemático más allá de la revisión manual puntual.
La revisión manual puntual no es un proceso de control de calidad. Es una lotería.
Los errores estructurales son los que vale la pena automatizar. Así es como se ven.
Los cinco tipos de verificaciones de control de calidad de localización
Cada cadena de traducción pasa por cinco verificaciones automatizadas antes de que un revisor humano la vea. Cada una detecta una clase de fallo que la revisión manual omite sistemáticamente.
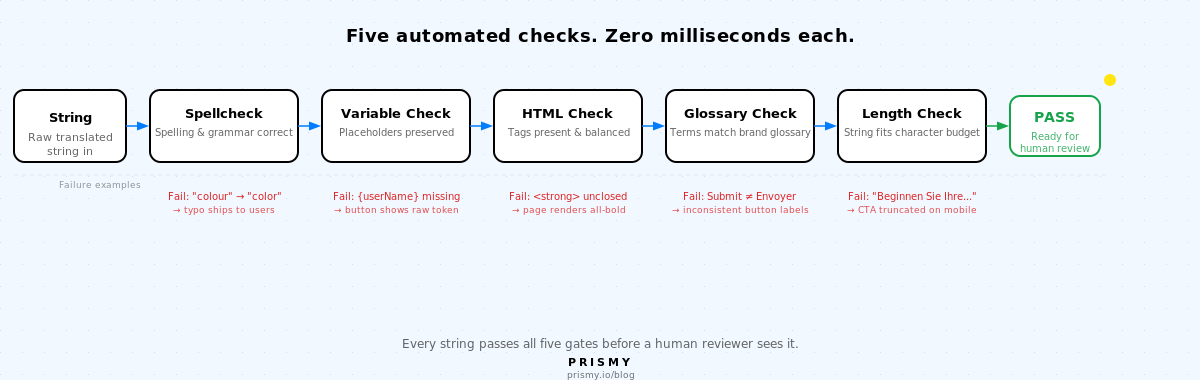
1. Corrección ortográfica
Cada clave de traducción debe estar libre de errores ortográficos y gramaticales.
El modo de fallo: una cadena traducida por IA o una edición humana introduce un error tipográfico, una forma verbal incorrecta o un desliz gramatical que pasa desapercibido porque nadie lo busca explícitamente. La revisión manual detecta muchos de estos, pero los revisores que leen para comprender el significado pasan por alto errores sutiles, especialmente en idiomas en los que no son completamente fluidos.
La corrección ortográfica automatizada se ejecuta en cada clave de traducción en cada locale antes de que la cadena llegue a un revisor. Marca errores ortográficos y problemas gramaticales básicos en menos de un milisegundo, a escala, en todos los idiomas en paralelo.
2. Preservación de variables
Cada marcador de posición de interpolación en la cadena fuente debe aparecer en la cadena traducida con el formato correcto.
El modo de fallo: un revisor nativo edita una cadena traducida por IA y renombra la variable: {userName} se convierte en {nombreUsuario}, o la omite completamente al reformular. La variable ya no se resuelve. En producción, los usuarios ven el marcador de posición sin procesar en lugar de su nombre. La traducción IA maneja esto correctamente; el error se introduce cuando un humano edita el resultado sin darse cuenta de que la variable es esencial.
Esto es automatizable con una simple coincidencia de patrones. La verificación se ejecuta en menos de un milisegundo. La misma encuesta reveló que el 61 % de los equipos ha experimentado variables de marcador de posición rotas en producción. Cada uno de esos fallos pasó una revisión humana.
3. Integridad de HTML y etiquetas
Cada etiqueta HTML en la cadena fuente debe estar presente y equilibrada en la traducción.
El modo de fallo: un traductor trabaja en modo de texto sin formato, o un sistema de traducción automática omite una etiqueta de cierre al reconstruir la cadena. La fuente dice Your subscription is <strong>active</strong>. La traducción dice Su suscripción está <strong>activa. Falta </strong>. El resto de la página se muestra en negrita.
Las verificaciones automatizadas de equilibrio de etiquetas detectan esto. El 41 % de los equipos ha enviado traducciones rotas que han interrumpido el diseño de la interfaz de usuario, según la misma encuesta. La pérdida de etiquetas HTML es una de las causas principales.
4. Coherencia del glosario
Cada término del glosario de marca debe aparecer con su traducción correcta en cada idioma, de forma coherente en todas las cadenas.
Sin una verificación del glosario, los traductores toman decisiones independientes a nivel de palabra. «Submit» se convierte en «Enviar» en una cadena y «Publicar» en otra. «Free trial» se convierte en «Prueba gratuita» en la página de precios y «Prueba de cortesía» en el flujo de incorporación. Los usuarios lo notan. Los tickets de soporte mencionan «el botón confuso».
El 58 % de los equipos informa de terminología incorrecta y términos inconsistentes como tipo de error de producción. La solución no son mejores traductores. Es un glosario que el evaluador verifica en cada cadena.
El trabajo real se realiza en el glosario. Necesitamos asegurarnos de que las traducciones de los términos clave sean correctas en el nuevo idioma. Es donde pasamos la mayor parte del tiempo.Alexis Toyane, Product Lead en Figures
Figures pasó de dos idiomas a nueve. El glosario no fue la carga. Fue el cimiento. Descubra cómo lo lograron: Figures escaló a nueve idiomas.
5. Longitud y desbordamiento
La cadena traducida debe caber en el elemento de interfaz de usuario que ocupará. El texto alemán es un 30-40 % más largo que el inglés. El japonés puede ser más corto pero requiere reglas de altura de línea diferentes.
Nadie verifica la longitud hasta que la cadena está en la aplicación en ejecución. El TMS muestra la cadena sin procesar, no el botón renderizado. Un llamado a la acción alemán que debería decir «Start your free trial» se convierte en «Beginnen Sie Ihre kostenlose...» y queda cortado en el borde del botón. El CTA principal es invisible en uno de sus principales mercados.
El 67 % de los equipos ha experimentado desbordamiento de texto y truncamiento en producción. Establecer presupuestos de caracteres por cadena y verificarlos a nivel de cadena detecta la larga cola antes del renderizado.
Por qué la revisión manual omite errores estructurales
Un revisor humano lee para comprender el significado. Detectará una falta de coincidencia de tono, un desliz cultural, una frase que suena torpe en portugués. No detectará {userName} sin resolver en la cadena porque inconscientemente lo lee como un valor completado.
Los revisores también trabajan a escala: 20-50 cadenas por hora es un ritmo realista para una revisión cuidadosa. Una versión de 50 cadenas en cinco idiomas significa 250 revisiones de cadenas. Las verificaciones estructurales se ejecutan en las mismas 250 cadenas en milisegundos.
Los datos de la encuesta de Common Sense Advisory de 2025 son directos: el control de calidad automatizado detecta el 70-80 % de todos los problemas de traducción, aumentando al 90-94 % para equipos con una gestión estricta del glosario. El 6-30 % restante es lingüístico y cultural, y requiere juicio humano. Esa es la división del trabajo.
El argumento económico lo cierra. Corregir un error de traducción después de que llega a producción cuesta 8-12 veces más que detectarlo durante la traducción (Nimdzi). Para un equipo que gestiona cinco idiomas con dos lanzamientos por mes, ese cálculo cambia rápidamente.
Tiene tres puntos de partida comunes:
Si está en un proceso manual: su revisor bilingüe detecta el 20 % lingüístico. El 80 % estructural se lanza. La variable que su revisor no notó está ahora frente a 2.000 usuarios alemanes.
Si está en un TMS empresarial: su pestaña de control de calidad existe, pero se ejecuta dentro de una plataforma. Si las cadenas se copian y pegan fuera del TMS antes de la implementación, la pestaña de control de calidad nunca las vio. Los errores estructurales salen por la puerta trasera.
Si está en un CLI solo para desarrolladores: su CI valida la sintaxis del archivo. No valida la preservación de variables, la integridad de etiquetas o la coherencia del glosario. Esas verificaciones requieren conocimiento del contenido de la cadena, no solo de su formato.
Cómo se ve un proceso sistemático de control de calidad de localización
Un proceso sistemático ejecuta las cinco verificaciones automatizadas en dos momentos y luego añade revisión humana encima:
Ejecute los cinco evaluadores de forma continua a medida que se actualizan los textos. Las verificaciones se ejecutan automáticamente en dos lugares. Cuando se generan las traducciones de IA, el motor de traducción de IA de Prismy ejecuta corrección ortográfica, preservación de variables, integridad HTML, coherencia del glosario y verificaciones de longitud en el momento de la generación: los errores estructurales nunca entran en los archivos de traducción. Inline mientras se edita, en la aplicación web de Prismy y en la extensión de Chrome, los editores ven los problemas marcados en tiempo real antes de confirmar un cambio. Corríjalo antes de lanzar, no después.
Ejecute los evaluadores una vez en sus textos existentes cuando configure Prismy por primera vez. La mayoría de los equipos tienen archivos de traducción construidos a lo largo de años: cadenas escritas por humanos, copiadas y pegadas entre herramientas, editadas sin evaluadores supervisando. Ese backlog tiene variables silenciosamente rotas, términos de glosario aplicados de forma inconsistente y longitudes que desbordan en pantallas que nadie verificó. Un pase de auditoría único los hace emerger antes de que salga en producción.
Los evaluadores de Prismy manejan ambos momentos automáticamente: corrección ortográfica, verificación de variables, integridad HTML, coincidencia de glosario y presupuesto de longitud se ejecutan en cada Pull Request nativo de Git e inline en el editor. Para la calidad de la traducción de IA que alimenta el proceso aguas arriba, consulte la guía completa.
-
Corrección ortográficaAutomatizableElija tres claves de traducción de sus locales más usadas y ejecútelas a través de una herramienta de corrección ortográfica. Los errores tipográficos y los deslices gramaticales que los revisores pasan por alto aparecen inmediatamente.
-
Preservación de variablesAutomatizableBusque en sus archivos traducidos cualquier
{,%o{{que aparezca en la fuente pero no en la traducción. Si encuentra uno, su proceso de control de calidad no lo detectó. -
Integridad de etiquetas HTMLAutomatizableEjecute una verificación de equilibrio de etiquetas en cualquier cadena traducida que contenga HTML. Un
<strong>o<a>no cerrado en producción propagará el estilo en negrita o de enlace por un párrafo. -
Coherencia del glosarioAutomatizableElija tres términos clave del producto (su CTA principal, el nombre de su producto, un nombre de función). Verifique si se traducen de la misma manera en cada cadena en cada idioma. Si no, necesita una verificación del glosario en su evaluador.
-
Longitud y desbordamientoAutomatizableCargue su producto en alemán u otro idioma de expansión larga. Verifique cada botón y etiqueta para detectar truncamiento. Si algo se corta, sus presupuestos de caracteres no se verifican en el momento del control de calidad.
FAQ
¿Cuál es la diferencia entre el control de calidad de localización y la revisión de traducción?
La revisión de traducción es una verificación humana de calidad: tono, precisión, fluidez. El control de calidad de localización incluye eso, más verificaciones mecánicas automatizadas: ortografía, variables, HTML, glosario, longitud. El control de calidad debe ejecutarse antes de la revisión humana, no en lugar de ella. La capa automatizada elimina los errores estructurales para que el revisor humano se concentre en el juicio.
¿Cómo se prueba la localización antes del lanzamiento?
Cuatro pasos: evaluadores automatizados en cada Pull Request (ortografía, variables, HTML, glosario, longitud), revisión humana en contexto en la aplicación en ejecución, una prueba de humo de lanzamiento ligera en un idioma y una auditoría trimestral del glosario para mantener las verificaciones automatizadas actualizadas con la terminología de su producto. Un sólido proceso de control de calidad de traducción también incluye pruebas de localización en contextos reales de dispositivos/pantalla para detectar problemas de desbordamiento y renderizado que las verificaciones a nivel de cadena no detectan.
¿Qué provoca fallos en el control de calidad de traducción en producción?
Generalmente no es el traductor. Generalmente es el proceso. Las variables faltantes se filtran cuando los traductores trabajan en texto sin formato sin evaluadores supervisando. La deriva del glosario ocurre cuando ninguna verificación hace cumplir la terminología. El desbordamiento de longitud ocurre cuando nadie prueba las cadenas renderizadas en una interfaz de usuario real. La mayoría de los errores de traducción de producción son estructurales, no lingüísticos, y la mayoría de los errores estructurales son automatizables.
¿Pueden las herramientas automatizadas reemplazar la revisión de traducción humana?
Para errores estructurales (ortografía, variables, HTML, glosario, longitud): sí, y lo hacen de forma más consistente y rápida que un humano. Para el juicio lingüístico (tono, adecuación cultural, matiz): no. Un proceso completo de control de calidad de localización usa ambos: las verificaciones automatizadas eliminan los fallos mecánicos, la revisión humana detecta los lingüísticos. La tasa de detección automatizada del 70-94 % deja el 6-30 % para que los revisores humanos se concentren.
¡No se pierda nuestras perspectivas del sector!
Reciba las últimas novedades sobre localización, traducciones con IA y actualizaciones de productos directamente en su bandeja de entrada.
Sin spam, puede darse de baja en cualquier momento. Respetamos su privacidad.

Globalícese de manera simple y poderosa.

© 2026 Prismy. Todos los derechos reservados.