21.05.2026 · Industry
Lokalisierungs-Qualitätssicherung für SaaS-Teams: Was vor dem Release geprüft werden muss
73 % der SaaS-Teams entdecken Fehler über Nutzerberichte, nicht durch QA. Lernen Sie, wie Lokalisierungs-QA defekte Variablen, HTML, Glossar und Länge aufdeckt.

Ein muttersprachlicher Reviewer bearbeitet eine KI-übersetzte Zeichenkette und benennt
{userName}in{benutzerName}um. Die Variable wird nicht mehr aufgelöst. Das Label zeigt jetzt{benutzerName}in der Produktion für jeden deutschen Nutzer. Die manuelle Prüfung hat es freigegeben: Der Reviewer las auf Bedeutung. Eine automatisierte Prüfung hätte es in unter einer Sekunde erkannt.
Was Lokalisierungs-Qualitätssicherung wirklich bedeutet
Lokalisierungs-Qualitätssicherung ist der Prozess der Überprüfung, ob Übersetzungen korrekt sind, bevor sie Nutzer erreichen. Sie umfasst sowohl die Übersetzungsqualitätssicherung (ist die Bedeutung korrekt?) als auch die strukturelle Integrität (sind Variablen, Tags und Glossarterme intakt?). Das sind zwei separate Aufgaben mit zwei verschiedenen Werkzeugen: automatisierte Prüfungen für strukturelle Fehler und menschliches Review für sprachliche Beurteilung.
Die meisten Teams vermischen beides. Sie senden Zeichenketten an ein zweisprachiges Teammitglied und betrachten die Aufgabe als erledigt. Der Reviewer erkennt Tonprobleme. Er erkennt keine fehlende Variable, weil er auf Bedeutung liest und keinen Musterabgleich durchführt.
Die Zahlen bestätigen dies. Eine Entwicklerumfrage von 2026 unter 1.000 Entwicklungs- und Produktteams ergab, dass 73 % Übersetzungsfehler in der Produktion über Nutzerberichte entdecken (IntlPull, State of i18n 2026). Nicht durch QA. Nicht durch Tests. Durch Nutzerbeschwerden. Dieselbe Umfrage ergab, dass 52 % keinen systematischen QA-Prozess jenseits manueller Stichproben haben.
Manuelle Stichproben sind kein QA-Prozess. Das ist eine Lotterie.
Strukturelle Fehler sind jene, die sich lohnen zu automatisieren. So sehen sie aus.
Die fünf Arten von Lokalisierungs-QA-Prüfungen
Jede Übersetzungszeichenkette durchläuft fünf automatisierte Prüfungen, bevor ein menschlicher Reviewer sie sieht. Jede erkennt eine Fehlerklasse, die manuelle Reviews konsistent übersehen.
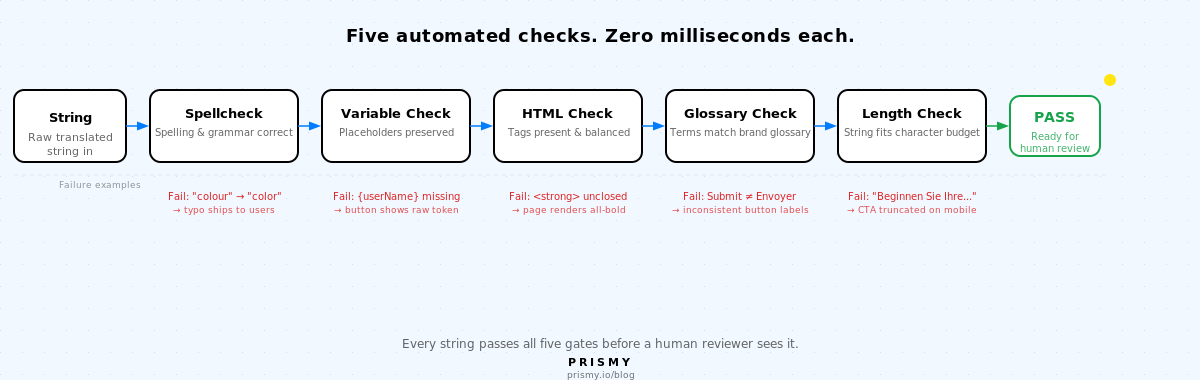
1. Rechtschreibprüfung
Jeder Übersetzungsschlüssel muss frei von Rechtschreib- und Grammatikfehlern sein.
Der Fehlermodus: Eine KI-übersetzte Zeichenkette oder eine menschliche Bearbeitung führt einen Tippfehler, eine falsche Verbform oder einen Grammatikfehler ein, der unbemerkt bleibt, weil niemand explizit danach sucht. Manuelle Reviews erkennen viele davon, aber Reviewer, die auf Bedeutung lesen, übersehen subtile Fehler: besonders in Sprachen, in denen sie nicht vollständig fließend sind.
Die automatisierte Rechtschreibprüfung läuft über jeden Übersetzungsschlüssel in jeder Locale, bevor die Zeichenkette einen Reviewer erreicht. Sie markiert Rechtschreibfehler und grundlegende Grammatikprobleme in unter einer Millisekunde, skaliert über jede Sprache parallel.
2. Variablenerhaltung
Jeder Interpolationsplatzhalter in der Quellzeichenkette muss in der übersetzten Zeichenkette mit dem korrekten Format erscheinen.
Der Fehlermodus: Ein muttersprachlicher Reviewer bearbeitet eine KI-übersetzte Zeichenkette und benennt die Variable um: {userName} wird zu {benutzerName}, oder er lässt sie beim Umformulieren vollständig weg. Die Variable wird nicht mehr aufgelöst. In der Produktion sehen Nutzer den rohen Platzhalter statt ihres Namens. KI-Übersetzung verarbeitet das korrekt; der Fehler wird eingeführt, wenn ein Mensch die Ausgabe bearbeitet, ohne zu erkennen, dass die Variable tragend ist.
Das ist mit einem einfachen Musterabgleich automatisierbar. Die Prüfung läuft in unter einer Millisekunde. Dieselbe Umfrage ergab, dass 61 % der Teams defekte Platzhaltervariablen in der Produktion erlebt haben. Jeder dieser Fehler hat ein menschliches Review bestanden.
3. HTML- und Tag-Integrität
Jedes HTML-Tag in der Quellzeichenkette muss in der Übersetzung vorhanden und ausgewogen sein.
Der Fehlermodus: Ein Übersetzer arbeitet im Nur-Text-Modus, oder ein maschinelles Übersetzungssystem lässt beim Rekonstruieren der Zeichenkette ein schließendes Tag weg. Die Quelle lautet Ihr Abonnement ist <strong>aktiv</strong>. Die Übersetzung lautet Votre abonnement est <strong>actif. Fehlendes </strong>. Der Rest der Seite rendert fett.
Automatisierte Tag-Balance-Prüfungen erkennen das. 41 % der Teams haben fehlerhafte Übersetzungen geliefert, die das UI-Layout gebrochen haben, laut derselben Umfrage. HTML-Tag-Verlust ist eine der häufigsten Ursachen.
4. Glossar-Konsistenz
Jeder Term im Markenglossар muss mit seiner korrekten Übersetzung in jeder Sprache erscheinen, konsistent über alle Zeichenketten.
Ohne Glossarprüfung treffen Übersetzer unabhängige Entscheidungen auf Wortebene. „Submit" wird in einer Zeichenkette zu „Senden" und in einer anderen zu „Absenden". „Free trial" wird auf der Preisseite zu „Kostenlose Testversion" und im Onboarding-Flow zu „Gratis testen". Nutzer bemerken das. Support-Tickets erwähnen „den verwirrenden Button".
58 % der Teams melden fehlerhafte Terminologie und inkonsistente Terme als Produktionsfehlertyp. Die Lösung sind keine besseren Übersetzer. Es ist ein Glossar, das der Evaluator bei jeder Zeichenkette prüft.
Die eigentliche Arbeit wird am Glossar geleistet. Wir müssen sicherstellen, dass Übersetzungen von Schlüsseltermen in der neuen Sprache korrekt sind. Dort verbringen wir die meiste Zeit.Alexis Toyane, Product Lead bei Figures
Figures skalierte von zwei Sprachen auf neun. Das Glossar war nicht der Aufwand. Es war das Fundament. Erfahren Sie, wie sie es geschafft haben: Figures skalierte auf neun Sprachen.
5. Länge und Überlauf
Die übersetzte Zeichenkette muss in das UI-Element passen, das sie belegen wird. Deutsches Texte ist 30 bis 40 % länger als Englisch. Japanisch kann kürzer sein, erfordert aber andere Zeilenhöhenregeln.
Niemand prüft die Länge, bis die Zeichenkette in der laufenden App ist. Das TMS zeigt die rohe Zeichenkette, nicht den gerenderten Button. Ein deutscher Call-to-Action, der „Start your free trial" lauten sollte, wird zu „Beginnen Sie Ihre kostenlose..." und wird am Buttonrand abgeschnitten. Der primäre CTA ist in einem Ihrer Top-Märkte unsichtbar.
67 % der Teams haben Textüberlauf und Abschneidung in der Produktion erlebt. Zeichenbudgets pro Zeichenkette festzulegen und diese auf Zeichenkettenebene zu prüfen, erkennt den Long Tail vor dem Rendern.
Warum manuelles Review strukturelle Fehler übersieht
Ein menschlicher Reviewer liest auf Bedeutung. Er erkennt eine Tonabweichung, einen kulturellen Fehler, einen Satz, der auf Portugiesisch hölzern klingt. Er erkennt nicht {userName}, das unaufgelöst in der Zeichenkette sitzt, weil er es unbewusst als ausgefüllten Wert liest.
Reviewer arbeiten auch skaliert: 20 bis 50 Zeichenketten pro Stunde ist ein realistisches Tempo für sorgfältiges Review. Ein Release mit 50 Zeichenketten über fünf Sprachen bedeutet 250 Zeichenketten-Reviews. Strukturelle Prüfungen laufen über dieselben 250 Zeichenketten in Millisekunden.
Die Daten aus der Common Sense Advisory-Umfrage von 2025 sind eindeutig: Automatisierte QA erkennt 70 bis 80 % aller Übersetzungsprobleme, steigt auf 90 bis 94 % für Teams mit striktem Glossarmanagement. Die verbleibenden 6 bis 30 % sind sprachlich und kulturell und erfordern menschliches Urteil. Das ist die Arbeitsteilung.
Das Kostenargument schließt das ab. Die Behebung eines Übersetzungsfehlers nach Erreichen der Produktion kostet 8 bis 12 Mal mehr als das Erkennen während der Übersetzung (Nimdzi). Für ein Team mit fünf Sprachen und zwei Releases pro Monat ändert sich diese Rechnung schnell.
Sie haben drei häufige Ausgangspunkte:
Wenn Sie einen manuellen Prozess haben: Ihr zweisprachiger Reviewer erkennt die sprachlichen 20 %. Die strukturellen 80 % werden geliefert. Die Variable, die Ihr Reviewer nicht bemerkt hat, steht jetzt vor 2.000 deutschen Nutzern.
Wenn Sie ein Enterprise-TMS haben: Ihr QA-Tab existiert, läuft aber innerhalb einer Plattform. Wenn Zeichenketten vor der Bereitstellung aus dem TMS kopiert werden, hat der QA-Tab sie nie gesehen. Die strukturellen Fehler verlassen durch die Hintertür.
Wenn Sie ein Dev-only-CLI haben: Ihr CI validiert die Dateisyntax. Es validiert nicht die Variablenerhaltung, Tag-Integrität oder Glossar-Konsistenz. Diese Prüfungen erfordern Bewusstsein für den Zeichenketteninhalt, nicht nur sein Format.
Wie ein systematischer Lokalisierungs-QA-Prozess aussieht
Ein systematischer Prozess führt die fünf automatisierten Prüfungen zu zwei Zeitpunkten durch und fügt dann menschliches Review hinzu:
Führen Sie die fünf Evaluatoren kontinuierlich aus, während Texte aktualisiert werden. Die Prüfungen laufen automatisch an zwei Stellen. Wenn KI-Übersetzungen generiert werden, führt Prismys KI-Übersetzungsmotor Rechtschreibprüfung, Variablenerhaltung, HTML-Integrität, Glossar-Konsistenz und Längеnprüfungen zum Generierungszeitpunkt durch: Strukturelle Fehler gelangen nie in die Übersetzungsdateien. Inline beim Bearbeiten, in der Prismy-Webapp und in der Chrome-Erweiterung, sehen Editoren Probleme in Echtzeit markiert, bevor sie eine Änderung einreichen. Beheben Sie es vor dem Release, nicht danach.
Führen Sie die Evaluatoren einmal auf Ihren bestehenden Texten aus, wenn Sie Prismy zum ersten Mal einrichten. Die meisten Teams haben Übersetzungsdateien, die über Jahre aufgebaut wurden: von Menschen geschriebene Zeichenketten, zwischen Tools kopiert, ohne Evaluatoren-Überwachung bearbeitet. Dieses Backlog hat still defekte Variablen, inkonsistent angewendete Glossarterme und Längen, die auf Bildschirmen überlaufen, die niemand geprüft hat. Ein einmaliger Audit-Durchlauf bringt das alles ans Licht, bevor Sie live gehen.
Prismys Evaluatoren verarbeiten beide Momente automatisch: Rechtschreibprüfung, Variablenprüfung, HTML-Integrität, Glossarabgleich und Längenbudget laufen auf jedem Git-nativen Pull Request und inline im Editor. Für die KI-Übersetzungsqualität, die den Prozess vorgelagert speist, lesen Sie den vollständigen Leitfaden.
-
RechtschreibprüfungAutomatisierbarWählen Sie drei Übersetzungsschlüssel aus Ihren meistgenutzten Locales und führen Sie sie durch ein Rechtschreibprüfungstool. Tippfehler und Grammatikfehler, die Reviewer überlesen, erscheinen sofort.
-
VariablenerhaltungAutomatisierbarDurchsuchen Sie Ihre übersetzten Dateien nach
{,%oder{{, das in der Quelle erscheint, aber nicht in der Übersetzung. Wenn Sie eines finden, hat Ihr QA-Prozess es nicht erkannt. -
HTML-Tag-IntegritätAutomatisierbarFühren Sie eine Tag-Balance-Prüfung auf allen übersetzten Zeichenketten durch, die HTML enthalten. Ein nicht geschlossenes
<strong>oder<a>in der Produktion wird Fett- oder Link-Styling über einen Absatz kaskadieren. -
Glossar-KonsistenzAutomatisierbarWählen Sie drei wichtige Produktterme (Ihr primärer CTA, Ihr Produktname, ein Funktionsname). Prüfen Sie, ob sie in jeder Zeichenkette über jede Sprache gleich übersetzt sind. Wenn nicht, benötigen Sie eine Glossarprüfung in Ihrem Evaluator.
-
Länge und ÜberlaufAutomatisierbarLaden Sie Ihr Produkt auf Deutsch oder einer anderen Sprache mit langer Expansion. Prüfen Sie jeden Button und jedes Label auf Abschneidung. Wenn etwas abgeschnitten ist, werden Ihre Zeichenbudgets zur QA-Zeit nicht geprüft.
FAQ
Was ist der Unterschied zwischen Lokalisierungs-QA und Übersetzungs-Review?
Übersetzungs-Review ist eine menschliche Qualitätsprüfung: Ton, Genauigkeit, Flüssigkeit. Lokalisierungs-Qualitätssicherung umfasst das plus automatisierte mechanische Prüfungen: Rechtschreibung, Variablen, HTML, Glossar, Länge. QA sollte vor dem menschlichen Review laufen, nicht statt ihm. Die automatisierte Ebene beseitigt strukturelle Fehler, damit sich der menschliche Reviewer auf Beurteilung konzentrieren kann.
Wie testen Sie die Lokalisierung vor dem Release?
Vier Schritte: Automatisierte Evaluatoren bei jedem Pull Request (Rechtschreibung, Variablen, HTML, Glossar, Länge), kontextuelles menschliches Review in der laufenden App, ein einfacher Release-Rauchtest über eine Sprache und ein vierteljährliches Glossaraudit, um die automatisierten Prüfungen mit Ihrer Produktterminologie aktuell zu halten. Ein solider Übersetzungs-QA-Prozess umfasst auch Lokalisierungstests in echten Geräte-/Bildschirmkontexten, um Überlauf- und Rendering-Probleme zu erkennen, die Prüfungen auf Zeichenkettenebene übersehen.
Was verursacht Fehler in der Übersetzungs-Qualitätssicherung in der Produktion?
Normalerweise nicht der Übersetzer. Normalerweise der Prozess. Fehlende Variablen schlüpfen durch, wenn Übersetzer im Nur-Text ohne Evaluatoren-Überwachung arbeiten. Glossardrift entsteht, wenn keine Prüfung die Terminologie erzwingt. Längenüberlauf entsteht, wenn niemand gerenderte Zeichenketten in einer echten Benutzeroberfläche testet. Die meisten Produktionsübersetzungsfehler sind strukturell, nicht sprachlich, und die meisten strukturellen Fehler sind automatisierbar.
Können automatisierte Tools das menschliche Übersetzungs-Review ersetzen?
Für strukturelle Fehler (Rechtschreibung, Variablen, HTML, Glossar, Länge): Ja, und sie tun es konsistenter und schneller als ein Mensch. Für sprachliches Urteil (Ton, kulturelle Passform, Nuance): Nein. Ein vollständiger Lokalisierungs-QA-Prozess nutzt beides: Automatisierte Prüfungen beseitigen mechanische Fehler, menschliches Review erkennt sprachliche Fehler. Die automatisierte Erkennungsrate von 70 bis 94 % lässt 6 bis 30 % für menschliche Reviewer übrig.
Verpassen Sie nicht unsere Branchen-Insights!
Erhalten Sie die neuesten Einblicke in Lokalisierung, KI-Übersetzungen und Produktupdates direkt in Ihren Posteingang.
Kein Spam, jederzeit abbestellbar. Wir respektieren Ihren Datenschutz.

Global gehen, auf einfache und kraftvolle Weise.

© 2026 Prismy. Alle Rechte vorbehalten.