29. April 2026 · Industry
KI-Lokalisierung 2026: Motor, Review und Zusammenarbeit
KI-Lokalisierung ist mehr als das Modell. Der echte Stack hat drei Schichten: Motor, Review und Zusammenarbeit. Ein Workflow-Leitfaden für SaaS-Teams in 2026.

Ein PM will das Wording eines Features in der Produktion verfeinern. Er durchsucht eine JSON-Datei nach den richtigen Schlüsseln, stört einen Entwickler, damit er ein Preview-Deployment anstößt, iteriert über die Formulierung, stößt die Übersetzung in fünf Sprachen erneut an und wartet auf ein weiteres Deployment. Ein halber Tag für zwei Wörter. Der Motor hat seinen Teil in Sekunden erledigt. Der Workflow drum herum ist das eigentliche Problem. Am Ende dieses Leitfadens haben Sie eine Drei-Schichten-Karte eines KI-Lokalisierungs-Stacks und ein 15-Minuten-Audit, das Sie morgen an Ihrem eigenen Setup durchführen können.
Was „KI-Lokalisierung" im Jahr 2026 wirklich bedeutet
KI-Lokalisierung ist der Einsatz von großen Sprachmodellen und Qualitätsevaluatoren, um Produkttexte mit der Geschwindigkeit von Releases zu übersetzen, anzupassen und zu prüfen. Es geht um mehr als Übersetzung. Ein funktionierender KI-Lokalisierungs-Stack verwaltet Glossar-Kontrolle, Markenstimme, Halluzinationserkennung und den Weg, über den neue Strings in die Produktion gelangen.
Der Motor hat eine echte Schwelle überschritten. Eine Meta-Evaluierung aus 2025 ergab, dass modernste Metriken nun die Übereinstimmungswerte menschlicher Bewerter für hochfrequente Sprachpaare erreichen oder übertreffen (arxiv 2506.19571, Juni 2025). Dieselbe Studie weist darauf hin, dass COMET flüssigen Halluzinationen großzügige Werte zuweist, sodass der Motor gut genug ist, um eingesetzt zu werden, aber nicht gut genug, um ihn unbeaufsichtigt zu lassen.
Marktdaten erzählen die gleiche Geschichte. Die Sprachdienstleistungs- und Technologiebranche erwirtschaftete im Jahr 2023 49,68 Milliarden US-Dollar, ein Rückgang von 4,5 Prozent gegenüber dem Vorjahr, wobei generative KI als Faktor genannt wurde (CSA Research, 2024). Die Arbeit wird erledigt. Die Frage ist, wer sie orchestriert. Für eine längere Perspektive lesen Sie unsere Einschätzung zur KI-Übersetzungsqualität in der Produktion.
Wenn der Motor gelöst ist, wo liegt der eigentliche Schmerz? In drei Schichten.
Der Drei-Schichten-Stack: Motor, Review und Zusammenarbeit
Jedes KI-Lokalisierungswerkzeug, vom selbst gebauten Python-Skript bis zur Unternehmensplattform, lässt sich drei Schichten zuordnen.
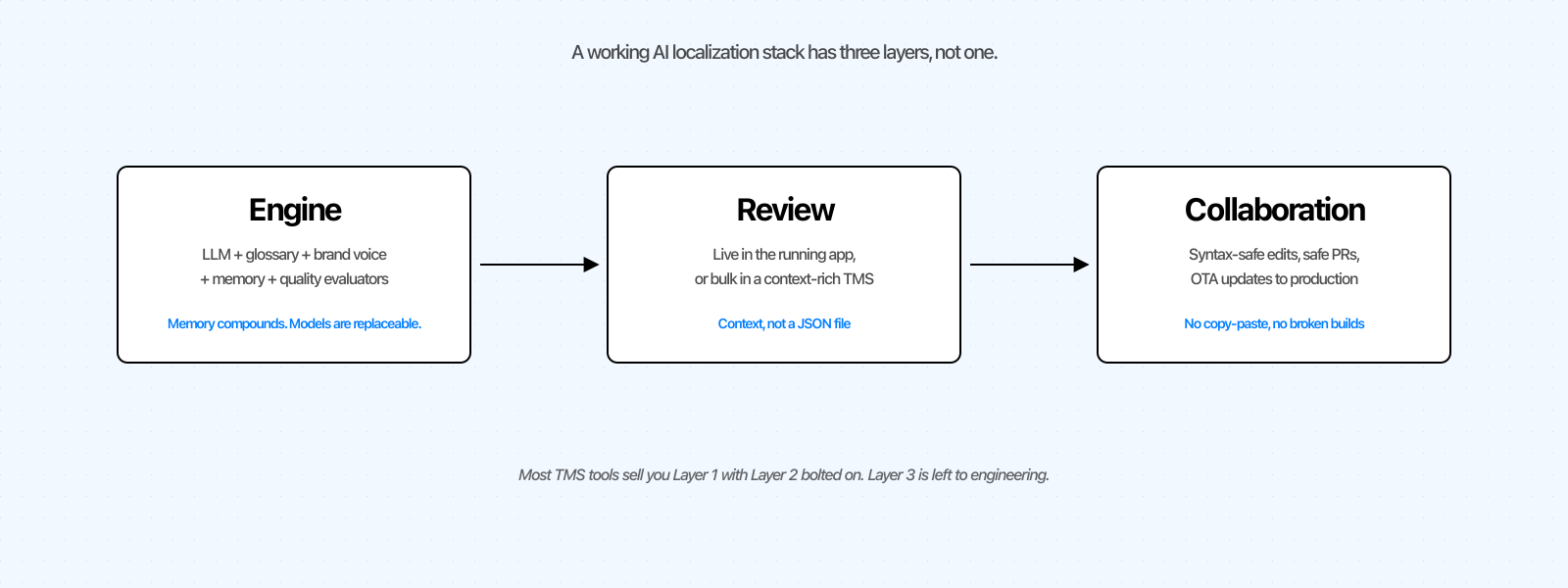
Motor. Das Modell, plus Glossar, Markenstimme, benutzerdefinierte Anweisungen, Übersetzungsspeicher und Qualitätsevaluatoren. Weitgehend standardisiert, mit einer Nuance: Speicher akkumuliert, Modelle nicht.
Review. Dort überprüft und verfeinert ein Mensch die KI-Ausgabe. Die meisten Werkzeuge wurden vor der KI entwickelt, als Übersetzer aus Tabellen arbeiteten, bevor das Feature ausgeliefert wurde. Das moderne Muster ist KI-zuerst: automatisch übersetzen, dann im Kontext prüfen.
Zusammenarbeit. Wie eine Textänderung sicher vom Review in die Produktion gelangt. Schlechte Zusammenarbeit ist ein Entwickler, der um 23 Uhr Strings in eine JSON-Datei kopiert. Gute Zusammenarbeit bedeutet, dass die Änderung die Produktion erreicht, ohne Syntaxfehler zu verursachen und ohne Personen zu stören, die nicht einbezogen werden mussten.
Wenn Sie von einer Tabelle kamen, haben Sie Schicht 1 selbst gemacht und nichts weiter. Wenn Sie von Lokalise oder Crowdin kamen, haben Sie die Schichten 1 und 2 in einem Produkt, aber eine synchronisierungsbasierte Schicht 3. Wenn Sie von Lingo.dev oder Languine kamen, haben Sie eine starke Schicht 1, eine CLI für Schicht 3 und keine echte Schicht 2 für Nicht-Entwickler.
Das richtige Werkzeug hängt davon ab, von welchem Ausgangspunkt Sie starten. Gehen wir jede Schicht durch.
Schicht 1: der Motor, größtenteils gelöst
Das Modell ist weniger wichtig als der Kontext, den es erhält. Ein Frontier-LLM mit einem Glossar, einem Markenstimmen-Profil und früheren Übersetzungen schlägt dasselbe Modell mit rohen Strings jedes Mal. Das Glossar sorgt dafür, dass „Submit" auf jeder Seite gleich übersetzt wird. Die Markenstimme hält die Formalität über Französisch und Deutsch hinweg konsistent. Benutzerdefinierte Anweisungen teilen dem Modell mit, dass „Stage" in Ihrem Produkt ein Pipeline-Schritt ist, keine Theaterbühne.
Der Übersetzungsspeicher ist das Teil, das die meisten Werkzeuge unterschätzen. Jede manuelle Bearbeitung ist ein Signal: So sagen wir es hier. Ein ernsthaftes System speichert diese Bearbeitungen, zeigt sie beim nächsten ähnlichen String an und identifiziert Muster, damit das Modell nicht immer wieder dieselben Korrekturen vornimmt. Je länger der Speicher läuft, desto weniger Arbeit hat der Reviewer. Das Modell ist ersetzbar. Der Speicher nicht.
Qualitätsevaluatoren sind das Sicherheitsnetz, das der Motor allein nicht bieten kann. Variablenerhaltung, HTML-Integrität, Glossar-Abweichungen, Längenbudgets. Diese werden automatisch ausgelöst und erfassen Fehler, die flüssig klingen, aber den Build brechen. Die Translated.com-Analyse weist darauf hin, dass COMET zuversichtlichen, aber untreuen Übersetzungen übermäßig großzügige Werte zuweist (Translated.com, 2025). Anbieter, die sich nur auf COMET stützen, lesen ihre eigene Reflexion.
Der Größenordnung nach: Smartling veröffentlichte eine Fallstudie, in der ein Fortune-100-Unternehmen in einem Jahr 3,4 Millionen US-Dollar einsparte und 50 Prozent schneller auslieferte (Smartling, 2026). Prismy liefert Glossar, Markenstimme, Übersetzungsspeicher und Evaluatoren sofort einsatzbereit (KI-Übersetzungsmotor).
Motoren sind standardisiert. Der eigentliche Schmerz liegt in Schicht 2.
Schicht 2: Review, live und im Kontext
Mein Reviewer verbrachte drei Stunden damit, KI-Ausgaben in einer JSON-Datei umzuschreiben, weil es keine Möglichkeit gab, die Strings im Kontext zu sehen.
Review-Oberfläche. Dort überprüft und verfeinert ein Nicht-Entwickler die KI-Ausgabe. Die beste ist die laufende App selbst.
Das ideale Review erfolgt live. Sie benutzen Ihr eigenes Produkt, entdecken einen Satz, der seltsam klingt, und korrigieren ihn sofort. Keine JSON-Datei, kein Dashboard, kein Entwickler im Weg. Ein Chrome-Overlay auf der Live-App ist der klarste Ausdruck: jeder String an Ort und Stelle bearbeitbar, mit dem umgebenden Bildschirm als Kontext.
Live-Bearbeitungen decken den langen Schwanz ab. Sie decken nicht den Fall ab, in dem ein professioneller Korrektor vierhundert Strings vor dem Launch in großen Mengen prüft. Diese Arbeit benötigt ein TMS. Der Engpass dort ist Kontextverlust: Eine Zeile Strings ohne Benutzeroberfläche drum herum lässt sich unmöglich gut übersetzen.
Prismy kombiniert ein TMS für den Massenfall mit Live-Vorschauen jedes Strings in der tatsächlichen Benutzeroberfläche und automatisch abgerufenen Screenshots der laufenden App. Das Massenformat, das der Korrektor benötigt, mit dem Kontext, der die Bearbeitung gut macht.

Die durchschnittliche Review-Zeit eines von Prismy verwalteten Strings beträgt 15 Minuten pro Sprache, gegenüber drei oder mehr Stunden, wenn der Reviewer den Kontext aus rohem JSON rekonstruiert. Die Zahl hat nichts mit Tippgeschwindigkeit zu tun. Es geht darum, nicht herausfinden zu müssen, wo jeder String im Produkt sitzt, bevor man ihn formuliert.
Wenn die Review-Oberfläche gelöst ist, bleibt die dritte Frage: Wie gelangt die Bearbeitung in die Produktion?
Schicht 3: Zusammenarbeit, die Änderung sicher in die Produktion bringen
Der Reviewer hat zwanzig Änderungen in der Tabelle vorgenommen und jetzt füge ich sie in die JSON-Datei ein. Ich habe eine schließende geschweifte Klammer vergessen und der Staging-Build ist rot.
Zusammenarbeit. Der Weg von „der Reviewer hat die Formulierung geändert" zu „die Änderung ist live in der Produktion", ohne dass ein Entwickler darauf aufpassen muss.
Stellen Sie sich den Tabellen-Workflow vor. Der Reviewer bearbeitet zwanzig Strings in einer gemeinsamen Tabelle. Ein Entwickler oder PM kopiert sie in die Codebasis. Eine Zeile bekommt ein überflüssiges Komma. Eine andere verliert eine {userName}-Variable. Der Build bricht. Multipliziert mit jedem Release, jeder Sprache, jedem Reviewer.
Gute Zusammenarbeit entfernt diese Schleife. Die Bearbeitung des Reviewers landet als kleiner Pull Request, den der Entwickler mit einem Klick zusammenführt. Drei Dinge machen es möglich:
- Syntaxsicherheit. Automatisch validiert: Variablen erhalten, HTML-Tags geschlossen, Glossar respektiert, Längenbudgets eingehalten. Eine Änderung, die die App brechen würde, erreicht den PR nie.
- Pull-Request-Übergabe. Der PR zeigt dem Entwickler genau, was geändert wurde, in derselben Diff-Ansicht, die er für Code verwendet. Lesen Sie mehr zum GitHub-Lokalisierungs-Workflow und zur GitLab-Integration.
- Over-the-Air-Updates. Für mobile und CDN-bereitgestellte Produkte bedeutet OTA, dass eine Textkorrektur um 17 Uhr an einem Freitag noch vor dem Wochenende in der Produktion landet, ohne ein App-Release.
Ein Series-A-IoT-Unternehmen berichtete, dass GitHub-Konflikte bei Übersetzungsdateien von einem wöchentlichen Problem auf null zurückgingen und dabei drei bis vier Tage pro Monat eingespart wurden. Crowdin veröffentlichte eine Polhus-Fallstudie mit 75 Prozent KI-generierten Übersetzungen, die ohne Bearbeitung genehmigt wurden, und einer Ersparnis von rund 80.000 US-Dollar (Crowdin, 2026).
Ein Entwickler sollte nie einen Dienstagnachmittag damit verbringen, Strings zu kopieren. Jetzt zur Build-oder-Kaufen-Entscheidung.
Build oder kaufen: ein Entscheidungsrahmen für KI-Lokalisierung
Kaufen Sie, wenn Sie in zwei oder mehr Sprachen ausliefern, zehn oder mehr Produktentwickler haben und Ihre Lokalisierung mehr als ein Konfigurations-Dump ist. Die Kosten einer fehlenden Review-Oberfläche summieren sich mit jeder Sprache und Persona, die Sie hinzufügen.
Bauen Sie, wenn Ihr Sicherheitsmodell den Zugang Dritter verbietet (selten, oft durch eine Hosted-Mode-Option gelöst) oder Sie einen regulierten Anwendungsfall haben. Andernfalls betragen die Kosten für den Aufbau aller drei Schichten sechs bis zwölf Monate Entwickleraufwand plus laufende Wartung.
Die Kosten eines schlechten Kaufs sind häufiger als die Kosten, keine Kaufentscheidung zu treffen. Ein Enterprise-TMS, das niemand nutzt. Eine CLI, die der PM nicht berühren kann. Ein Tabellen-Workflow, der bei Sprache fünf abbricht. Die Entscheidung ist nicht „bestes KI-Übersetzungswerkzeug". Sie ist „welcher Workflow passt zu meinem Team".
Die Meinung, für die dieser Beitrag argumentiert: KI-Übersetzungsqualität ist gelöst. Das eigentliche Produkt ist der Workflow. Wählen Sie das Werkzeug, dessen Review-Oberfläche und Zusammenarbeits-Flow zu der Art passen, wie Ihr Team bereits arbeitet, nicht das mit der längsten Feature-Liste. Wenn Sie Werkzeuge noch ausschließlich nach Motor-Qualität bewerten, beantworten Sie die gestrige Frage.
Ein 15-Minuten-KI-Lokalisierungs-Audit
Führen Sie dieses an Ihrem eigenen Setup durch. Jedes „Nein" ist ein Ort, an dem Ihr Entwickler Lokalisierungsarbeit übernimmt, die jemand anderes erledigen sollte, oder wo ein Release stoppt, weil die Texte nicht bereit sind.
Das 7-Fragen-Audit
Meist Nein = Ihr Stack kostet Sie EntwicklerstundenSchnelle Selbsteinschätzung für Produkt-Engineering- und Lokalisierungsleiter.
- MotorHaben Sie ein Glossar, das der PM ohne Ticket bearbeiten kann?
- MotorKennzeichnet Ihr Werkzeug fehlerhafte Variablen, fehlendes HTML oder Glossar-Abweichungen vor dem Zusammenführen?
- ReviewKann Ihr UX-Texter Formulierungen in Figma, im Kontext des Designs, prüfen?
- ReviewKann ein Muttersprachler-Reviewer einen String in der Live-App verfeinern, ohne eine JSON-Datei anzufassen?
- ZusammenarbeitÖffnet Ihr Werkzeug einen sauberen Git-PR für neue Strings, ohne manuellen Kopieraufwand?
- ZusammenarbeitWenn ein französischer String am Freitag um 17 Uhr falsch ist, kann ein Nicht-Entwickler ihn in der Produktion korrigieren, ohne den Entwickler zu stören?
- SkalierungKann Ihr Team eine sechste Sprache hinzufügen, ohne Personal einzustellen?
Meist „Nein"? Prismy wurde genau dafür entwickelt. Verbinden Sie GitHub oder GitLab und liefern Sie noch am selben Tag Ihren ersten KI-Übersetzungs-PR aus.
Prismy entdecken →Die Skalierungsfrage ist nicht theoretisch. Alexis, Figures: „Von zwei Sprachen auf fast zehn mit wunderbarer Konsistenz." Dieses Team wechselte von einem Ad-hoc-Setup mit zwei Sprachen zu einem Neun-Sprachen-Produktions-Stack, ohne eine Lokalisierungsrolle hinzuzufügen. Wenn Ihr Stack Sie nicht dorthin bringen kann, haben Sie ein Workflow-Problem, kein Motor-Problem.
FAQ
Was ist KI-Lokalisierung?
KI-Lokalisierung ist der Einsatz von LLMs und Qualitätsevaluatoren, um Produkttexte mit der Geschwindigkeit von Releases zu übersetzen, anzupassen und zu prüfen. Sie umfasst Glossar-Kontrolle, Markenstimme, Übersetzungsspeicher, Halluzinationserkennung und sichere Übergabe an die Produktion.
Wie unterscheidet sich KI-Lokalisierung von maschineller Übersetzung?
Maschinelle Übersetzung ist der Motor allein: Quelle rein, Ziel raus. KI-Lokalisierung ist der Motor plus der Workflow: Glossar, Markenstimme, Übersetzungsspeicher, Review-Oberflächen und ein Git-nativer oder OTA-Zusammenarbeits-Pfad.
Ist KI-Übersetzung gut genug für die Produktion?
Für hochfrequente Sprachen und Produkttexte ja, mit Qualitätsevaluatoren und menschlichem Review darüber. Für rechtliche, medizinische oder kreative Inhalte noch nicht. Die Literatur aus 2025 zeigt Motor-Parität bei gängigen Sprachpaaren neben Halluzinations-Blindflecken.
Kann KI menschliche Übersetzer ersetzen?
Nein. KI übernimmt das Erstübersetzungsvolumen. Menschen übernehmen Nuancen, Markenstimmen-Review und hochriskante Inhalte. Die Wirtschaft verlagert sich von der Übersetzung hin zum Review.
Wie viel kostet KI-Lokalisierung?
Die Motor-Kosten betragen etwa ein bis drei Cent pro String mit einem Frontier-LLM. Die meisten Einsparungen gegenüber einem TMS entstehen bei Review und Zusammenarbeit, nicht beim Modell. Eine Reduzierung der Gesamtausgaben um 50 Prozent ist eine gängige Größenordnung.
Was ist die beste KI-Lokalisierungsplattform im Jahr 2026?
Keine einheitliche Antwort. Motor-zuerst, wenn Sie ein Managed-Services-Budget haben. Workflow-zuerst, wenn Sie aus Git ausliefern und PMs, UX-Texter und Reviewer in der Schleife brauchen.
Verpassen Sie nicht unsere Branchen-Insights!
Erhalten Sie die neuesten Einblicke in Lokalisierung, KI-Übersetzungen und Produktupdates direkt in Ihren Posteingang.
Kein Spam, jederzeit abbestellbar. Wir respektieren Ihren Datenschutz.

Global gehen, auf einfache und kraftvolle Weise.

© 2026 Prismy. Alle Rechte vorbehalten.